Paper Explained 1: Convolutional Neural Network for Sentence Classification
Chào mọi người, ở trong số đầu tiên, chúng ta sẽ tìm hiểu về cách thức mà một mạng CNN (vốn rất nổi tiếng trong các bài toán xử lí ảnh) lại có thể áp dụng được vào trong bài toán xử lí ngôn ngữ tự nhiên, mà ở đây cụ thể là bài toán phân loại câu mà vẫn cho ra một kết quả tốt. Và cũng như trong bài này, chúng ta sẽ bàn luận thêm về các ưu nhược điểm cũng như các cách khác mà ta có thể cải tiến được kết quả của mô hình này.
Mọi người có thể đọc bài báo gốc ở đây.
Giới thiệu
Để có thể hiểu được bài viết này, sẽ có một vài khái niệm mà mọi người sẽ cần phải biết trước để không bị “ủa là sao ta??!” (biết trước ở đây là mọi người biết được cái công dụng của nó là đủ để hiểu rồi). Các khái niệm đó sẽ bao gồm lớp embedding, convolution, pooling, linear. Nhưng không sao, mọi người cứ bấm vào link trong mỗi từ, mình thấy mấy cái trang này giải thích cũng ok.
!!! Clarify !!!: Ban đầu là mấy mạng CNN dùng để xử lý ảnh, nhưng mà cũng có vài bài nghiên cứu mang CNN ra khỏi khuôn khổ của xử lí ảnh, họ chuyển nó sang để giải quyết mấy bài toán bên NLP như là semantic matching hay là search query retrieval hay là những bài toán NLP cơ bản khác. Ở đây có một điểm rất thú vị là khi nhắc đến mạng CNN cho chữ thì mọi người nghĩ ngay đến cái bài mà mình vừa link ở trên, nhưng thật ra có một bài viết nền tảng cho cái này mà mình nghĩ mọi người cũng nên quan tâm đó là bài “A Convolutional Neural Network for Modelling Sentences”. Cũng như là một bài khác mà mô mình này lấy cảm hứng đó là bài “Natural Language Processing (almost) from Scratch”. Mình nghĩ hai bài này là nền tảng cho cái bài mà tụi mình phân tích ngày hôm nay
Cách mạng TextCNN hoạt động
Biểu diễn chữ dưới dạng vector
Đầu tiên chúng ta cần hiểu word embedding là gì, nếu như các bạn đã hiểu cụ thể nó là gì (hoặc chưa hiểu thì link về embedding ở trên là một nguồn đọc rất tốt) thì tóm gọn lại là việc chúng ta biểu diễn một chữ dưới dạng vector. Như hình vẽ sau:
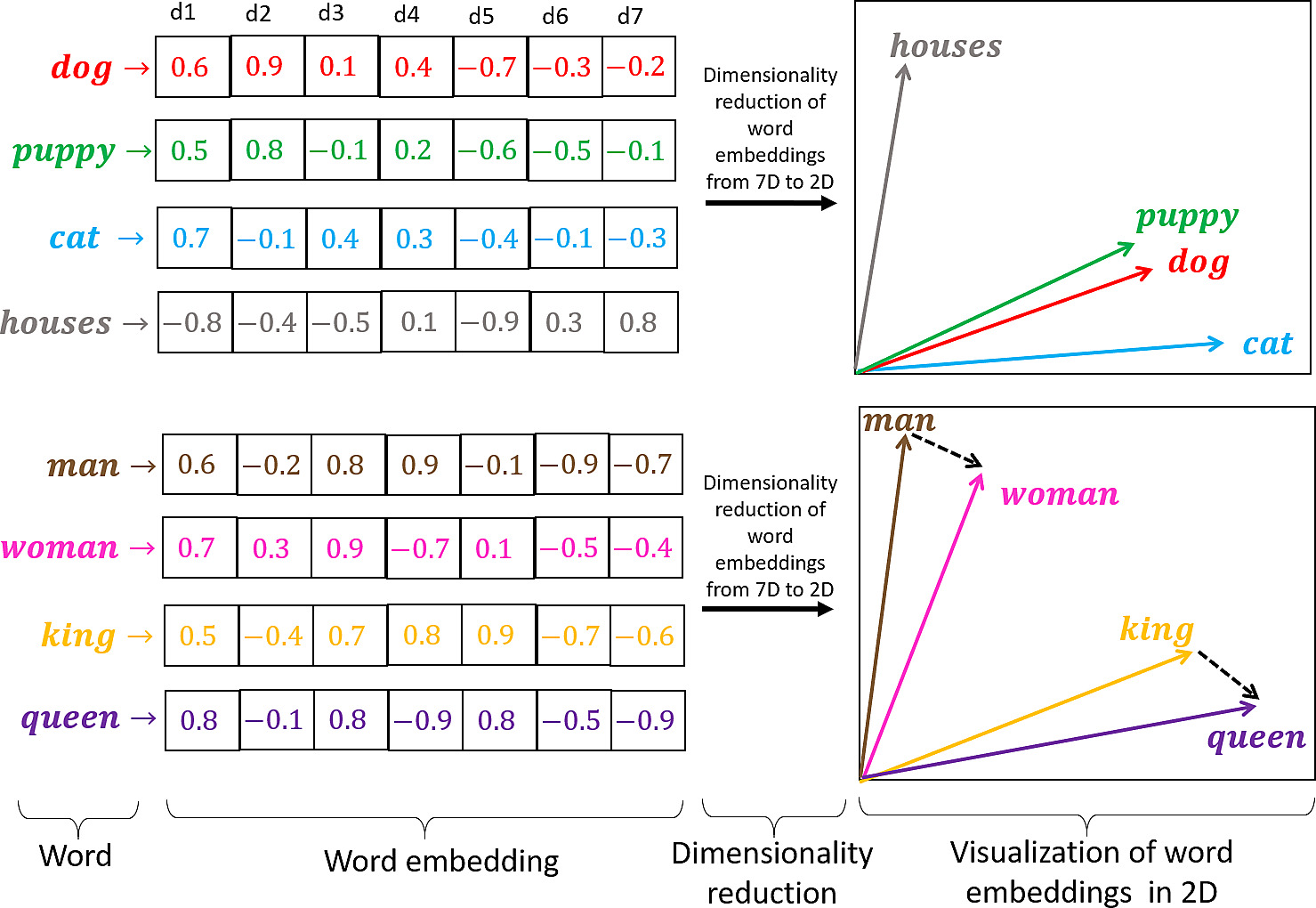
Như trong hình vẽ trên thì một chữ của chúng ta sẽ được biểu diễn thành một vector có 7 phần tử (số chiều là 7). Thật ra thì số chiều này là bao nhiêu cũng được, đây là một siêu tham số mà mọi người có thể chọn, với cách nghĩ thông thường thì với một số chiều càng lớn, các từ của chúng ta được biểu diễn bởi một vector dài hơn, do đó mà nắm bắt được nhiều ngữ nghĩa của từ hơn, và cũng như vậy, một số chiều dài hơn tương đương với chi phí tính toán cao hơn. Và cũng trong hình vẽ này, nếu như các chữ được biểu diễn tốt (biểu diễn tốt ở đây là các chữ cùng liên quan tới một nghĩa hay có cái sự liên quan mà mọi người đọc qua thấy cũng hợp lí) thì sẽ có khoảng cách ngắn, hay hiểu là chúng nằm gần nhau cũng được, giống như ‘puppy’ với ‘dog’ cùng có nghĩa là con chó, kiểu kiểu vậy 🥲.
Ok vậy câu hỏi tiếp theo là giá trị của mấy phần tử này người ta lấy ở đâu? Thì câu trả lời là người ta sẽ random cho mọi người nha, random trong khoảng từ -1 tới 1 trong trường hợp của hình vẽ. Còn trong bài nghiên cứu mà chúng ta tìm hiểu thì các biểu diễn của từ này được lấy từ một mô hình ngôn ngữ học không giám sát trên tập dữ liệu Google News của Mikolov et al.
Câu hỏi tiếp theo là tại sao phải làm vậy? Thì câu trả lời đơn giản là 100 tỷ từ được huấn luyện trên tập dữ liệu Google News đã là các chữ được biểu diễn tốt như mình đề cập ở trên, và hơn nữa, làm như vậy sẽ tối ưu hơn việc mà chúng ta chỉ tạo ngẫu nhiên giá trị cho từng phần tử của trong vector của mỗi từ (hiểu nôm na là ngẫu nhiên thôi thì mấy cái từ tự nhiên có ý nghĩa gì đâu 🤨).
Về mô hình
Cấu trúc mô hình này khá đơn giản, chúng ta sẽ xem tổng quan mô hình ra sao rồi sau đó đào sâu hơn về mặt toán học cũng như cách mà mô hình này hoạt động, các cách biểu diễn đầu ra, đầu vào là như thế nào,v.v…. Dưới đây là cấu trúc mô hình:
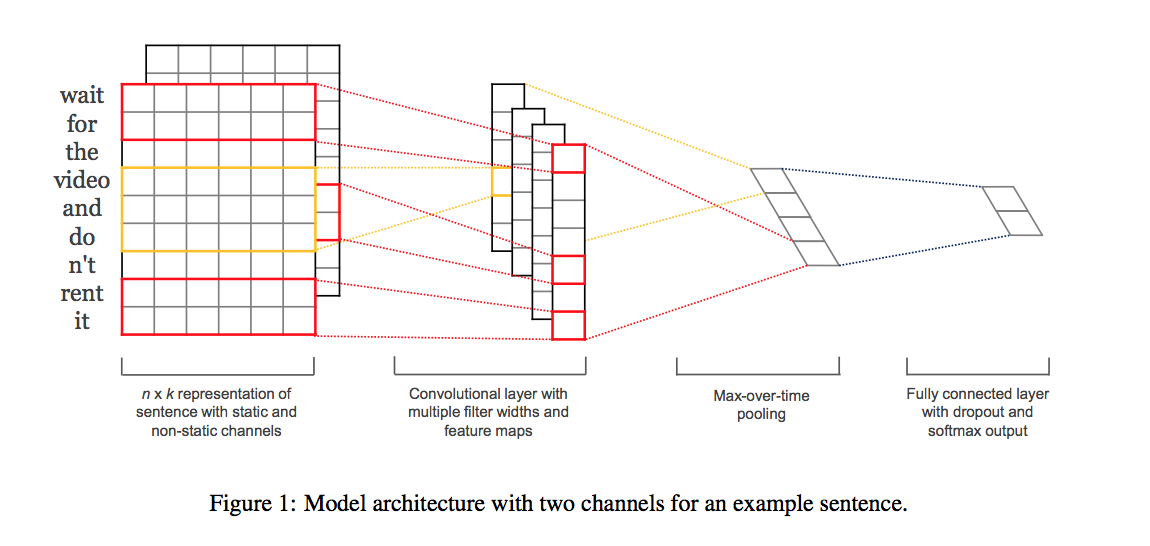
Hình trên được lấy từ bài paper tụi mình sẽ nghiên cứu, nên là, tin chuẩn nhế mọi người 🍻
Biểu diễn đầu vào
Như hồi nãy mình có nói là các chữ được biểu diễn dưới dạng vector, mà cụ thể hơn thì có dạng $\mathbf{x}_i \in \mathbb{R}^k$ với i là thứ tự của chữ đó trong câu, còn k là số chiều của vector thứ i đó.
Nếu một từ được biểu diễn dưới dạng một vector như vậy thì ở đây một câu sẽ biểu diễn dưới dạng của …ma trận (rõ ràng luôn 😎👌). Cụ thể hơn thì một câu có độ dài là n từ thì sẽ được biểu diễn như sau:
\[\mathbf{x}_{(1:n)} = \mathbf{x}_1 \oplus \mathbf{x}_2 \oplus \mathbf{x}_3 \oplus \ldots \oplus \mathbf{x}_n\]Trong đó thì $\oplus$ là phép toán concatenation (phép toán ghép) và để khái quát hơn cho trường hợp của một câu, lấy ví dụ ta không quan tâm tới toàn bộ câu, mà chỉ một đoạn nhỏ trong câu thôi thì ta cũng có thể biểu diễn dưới công thức toán như sau:
\[\mathbf{x}_{(i:j)} = \mathbf{x}_i \oplus \mathbf{x}_{i+1} \oplus \mathbf{x}_{i+2} \oplus \ldots \oplus \mathbf{x}_j\]Giờ lấy ví dụ mình có một câu hoàn chỉnh là: I think your shirts look nice, i like it thì mình chỉ chọn ra từ đoạn your tới đoạn nice thôi, nếu mình làm như vậy thì mình sẽ có một ma trận như bên dưới:
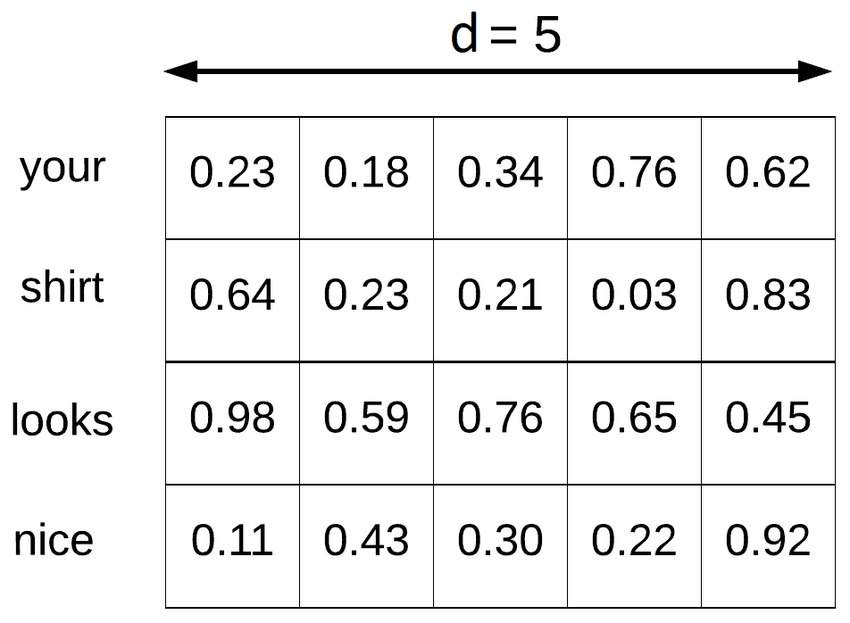
Convolution (tích chập) và output (đầu ra)
Như vậy thì giờ chúng ta đã hiểu đầu vào của thuật toán sẽ được biểu diễn dưới dạng của một ma trận n x k. Giờ mình nói tiếp phép convolution cũng như là cách mà chúng ta có được đầu ra của phép convolution.
Có lẽ mọi người cũng đã hiểu cái filter mà người ta thường nói trong các phép convolution là gì (nếu chưa thì xem cái link ở đầu nha 🥹). Thì với mô hình hiện giờ của chúng ta, cái filter được định nghĩa một ma trận như: $\mathbf{w} \in \mathbb{R}^{h \times k}$ với h là số từ, còn k là chiều của vector biểu diễn từ như hồi nãy mình có nói.
Với những cái thông tin mình cung cấp về đầu vào và filter. Filter mà mình vừa đề cập sẽ thực hiện phép convolution với một ma trận h từ để đưa ra một feature (thuộc tính) mới, lấy ví dụ là $c_{i}$ được tính như sau:
\[c_{i} = \sigma(\mathbf{w} * \mathbf{x}_{(i:i+h)} + b)\]Ở đây, $\sigma$ là một hàm phi tuyến nào đó, lấy ví dụ như là hàm tanh hoặc là hàm ReLU, b là bias (không biết dịch cái này kiểu gì 🤷♂️). Và đó là cách mà từ một cái filter, đầu vào, mà chúng ta ra được một con số đại diện cho cái đoạn h từ đó. Nhưng không chỉ dừng lại ở đó, ta có thể áp cái cục filter này vào từng cửa sổ h từ trong câu sao cho nó duyệt qua hết tất cả các cửa sổ h từ trong câu với biểu diễn toán học là \(\{\mathbf{x}_{(1:h)}, \mathbf{x}_{(2:h+1)}, \ldots, \mathbf{x}_{(n-h+1:n)}\}\) để tạo ra một cái feature map (biểu diễn đặc trưng) tương ứng cho câu. Và như vậy, chúng ta có một vector hoàn chỉnh đại diện cho câu như công thức sau:
Sau khi đã có vector $\mathbf{c}$ này rồi, chúng ta thực hiện phép max pooling (gộp cực đại) để lấy ra feature đại diện cho cái filter cụ thể mà chúng ta đang xét này: \(c_{\text{max}} = \max(\mathbf{c}).\) Chúng ta làm vậy bởi vì chúng ta tin rằng đặc trưng quan trọng nhất của mỗi feature map là đặc trưng có giá trị lớn nhất.
Vậy còn “mỗi feature map ?”. “mỗi” là bởi vì chúng ta sẽ không sử dụng duy nhất một filter, mà chúng ta sẽ có nhiều filter khác nhau, và đặc điểm của các filter này là chúng sẽ có kích thước khác nhau (khác nhau ở số từ mà chúng ta sẽ lấy ở từng filter). Nghe hơi lằng nhằng đúng không? Không sao, hình dưới đây sẽ giải thích được cái đó:
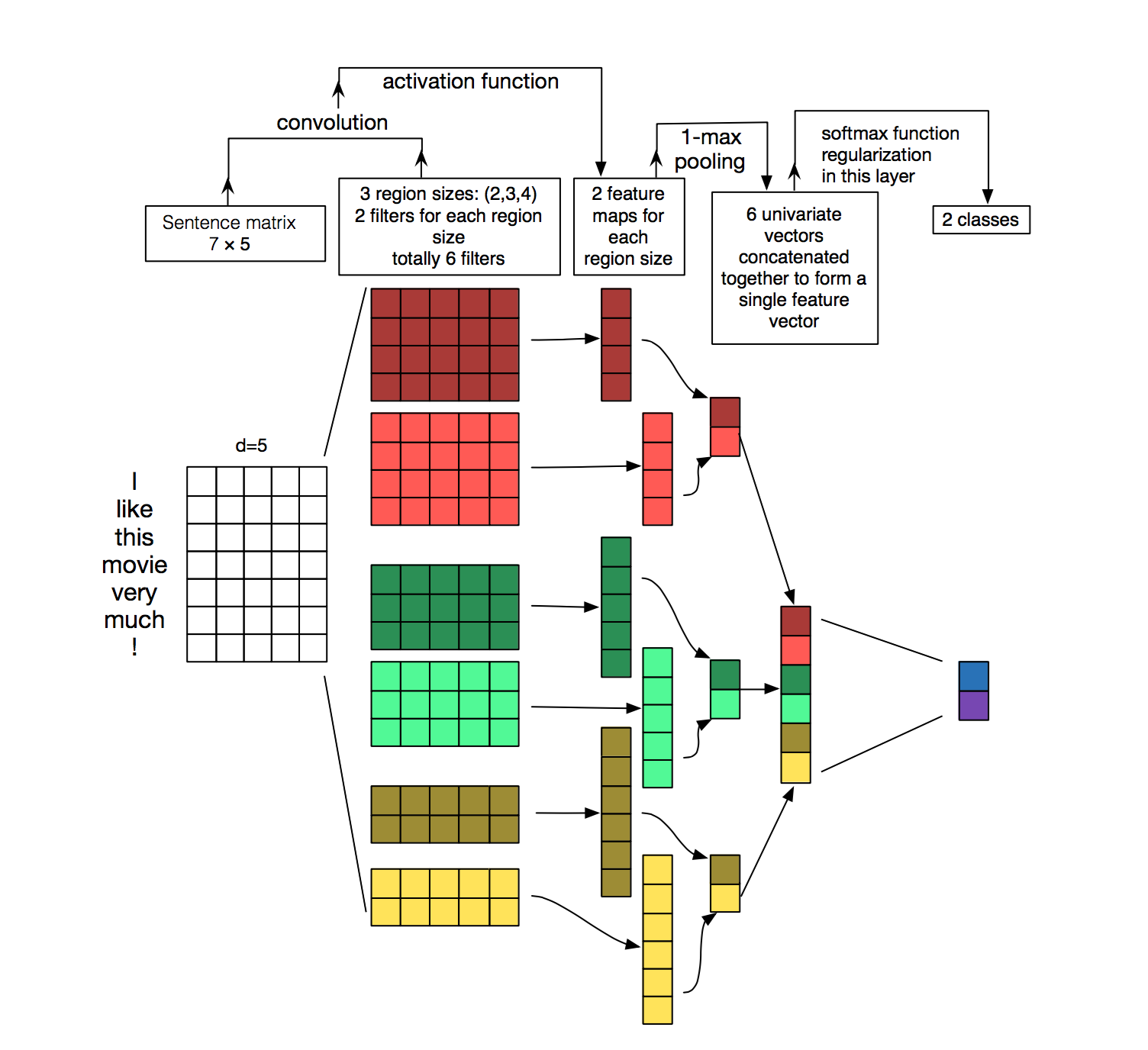
Cái hình này về cơ bản cũng là mô hình mà chúng ta đang xây dựng, là bản “nhiều màu sắc” so với mô hình mà được đề cập ở trên. Mọi người để ý nó có mấy cục filter nhiều màu đó không? Đó là cái mình vừa nói, tức là chúng ta sẽ sử dụng những filter khác nhau với kích thước khác nhau (là mấy cục nhiều màu đó đó).
Giờ, ứng với mỗi filter khác nhau, ta thực hiện phép convolution giữa mỗi filter đó với ma trận đầu vào, sẽ cho ra các vector có kích thước khác nhau, tùy thuộc vào kích cỡ của cái filter, và sau đó, thực hiện max pooling, ta sẽ thu được feature đại diện mà lúc trước được đề cập đến.
Vậy ý nghĩa của việc cần các filter khác nhau là gì? Câu trả lời là mô hình sẽ sử dụng nhiều filter khác nhau để nắm bắt đưuọc nhiều thông tin khác nhau trong câu (còn thông tin đó là gì thì chúng ta chưa biết được) theo như tác giả giải thích. Còn tại sao lại như vậy thì hiện tại chưa có câu trả lời, do đó cần thêm các nghiên cứu chuyên sâu khác về vấn đề này. Nhưng theo mình, việc chúng ta có nhiều parameters hơn cũng đồng nghĩa với việc mô hình trở nên đa dạng hơn, còn về việc các filter sẽ thay đổi như thế nào là phụ thuộc vào việc chúng ta xác định cái objective của chúng ta là gì. Còn lại, cứ để mô hình lo 🤡🤡🤡. Bên lề là có một bài viết cũng hay về chủ đề này, mọi người có thể đọc thêm ở đây
Perceptron đa tầng (multilayer perceptron)
Nói nôm na, đây là một loại mạng nơ-ron nhân tạo (ANN) có cấu trúc gồm nhiều lớp ẩn, mỗi lớp chứa một số lượng nút nhất định. Và trong trường hợp của chúng ta thì các feature cuối cùng (sau khi đã qua giai đoạn max pooling) sẽ được ghép lại với nhau để tạo ra một vector đại diện cuối cùng với mỗi phần tử trong vector là một nút.
Vector đại diện này sẽ được truyền qua lớp fully connected layer (kết nối đầy đủ) và sử dụng hàm phi tuyến softmax để đưa giá trị đầu ra trở thành các con số xác suất có tổng bằng 1.
Regularization (cơ chế kiểm soát)
Để đưa ra một cái nhìn tổng quát ở đoạn này, mình xin trích lại một đoạn từ trong cuốn sách “Deep Learing” của Ian Goodfellow và cộng sự: cơ chế kiểm soát là “bất kỳ sự điều chỉnh nào trong thuật toán học tập nhằm giảm sai số tổng quát hóa, không nhằm giảm sai số huấn luyện”. Có nhiều cơ chế kiểm soát khác nhau, nhưng ở đây nhóm tác giả sẽ sử dụng 2 cơ chế kiểm soát chính là l2 regularization(cơ chế phạt chuẩn l2) và dropout(cơ chế tắt ngẫu nhiên)
Hàm phạt chuẩn $L^{2}$ còn được biết đến với tên gọi khác là suy weight decay (suy giảm trọng số) và ý nghĩa của nó hiểu nôm na là nó sẽ thêm một đại lượng kiểm soát vào objective function (hàm mục tiêu) để hướng trọng số mô hình về gần gốc tọa độ (thật ra là không về bất kì điểm nào trong không gian cũng được chứ không nhất thiết phải là gốc tọa độ). Objective function sau khi kết hợp với l2 regularization sẽ được định nghĩa như hình dưới đây:

Ý nghĩa của việc này (mình trích lại từ cuốn sách về đề cập) là: Bộ kiểm soát $L^{2}$ khiến cho thuật toán học tập “nhận thức” rằng giá trị đầu vào $\mathbf{X}$ có phương sai lớn hơn, khiến nó làm co trọng số của các đặc trưng có hiệp phương sai đối với nhãn đầu ra có giá trị nhỏ so với giá trị phương sai mới.
Về dropout, nói nôm là, cơ chế này hỗ trợ huấn luyện mô hình bằng cách loại bỏ các hidden units(đơn vị ẩn), điều này buộc mô hình phải học cách phụ thuộc vào các đơn vị khác nhau, thay vì phụ thuộc vào một số đơn vị cụ thể. Ví dụ, nếu chúng ta có một mạng nơ-ron có 100 đơn vị, chúng ta có thể sử dụng dropout với tỷ lệ 20%. Điều này có nghĩa là trong mỗi lần cập nhật tham số, chúng ta sẽ ngẫu nhiên loại bỏ 20% các đơn vị trong mạng. Lấy ví dụ trong hình ảnh sau:
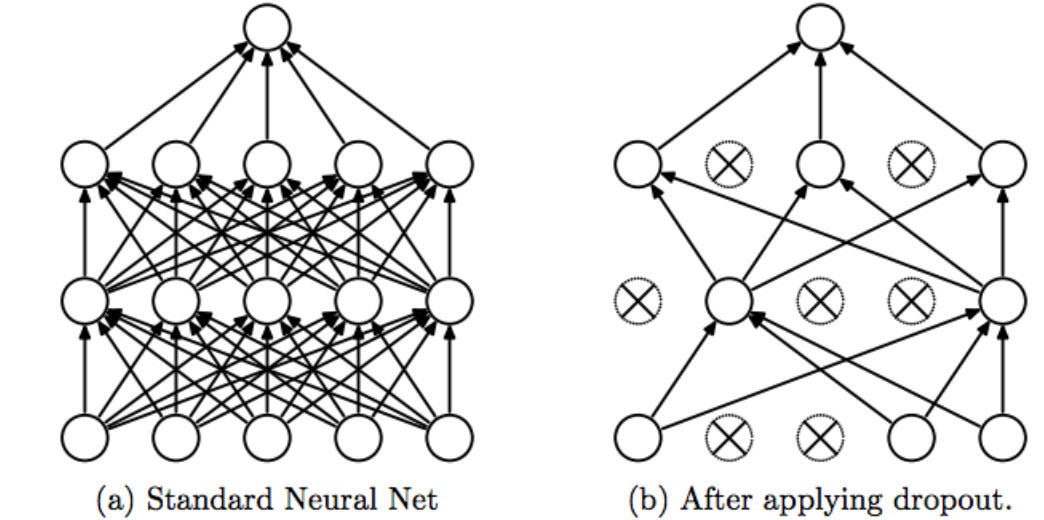
Ok, như vậy chúng ta đã hiểu sơ sơ về các phương pháp kiểm soát mà nhóm tác giả sử dụng, giờ chúng ta sẽ tìm hiểu rõ hơn cách mà các tác giả làm điều đó. Mọi người nhớ lại vector đại diện cuối cùng đã được đề cập ở phần Perceptron đa tầng. Mình đã nói là nó sẽ đi qua một cái FCL, và áp dụng hàm phi tuyến sigmoid, như vậy công thức toán học của nó là:
\[y = \mathbf{w} \cdot \mathbf{z} + b\]Trong đó $\mathbf{z}$ là một vector gồm m phần tử với m là số lượng filter mà chúng ta xài. Do đó mà vector này được định nghĩa: $\mathbf{z} \in \mathbb{R}^m$. Nhưng như đã đề cập, chúng ta có sử dụng dropout, do đó mà chúng ta cần phải mask (che) đi vài đơn vị ẩn. Biểu diễn đơn giản dưới công thức toán học, lúc này $y$ sẽ là:
\[y = \mathbf{w} \cdot (\mathbf{r} \odot \mathbf{z}) + b\]Ở công thức trên, $\mathbf{r}$ là một vector có m-chiều với m ở đây cũng chính là số lượng filter mà mô hình sử dụng và được biểu diễn cụ thể dưới dạng toán học như sau: $\mathbf{r} \in \mathbb{R}^m$ . Và các phần tử của vector này có thể xem là các biến ngẫu nhiên tuân theo phân phối Bernoulli với xác suất p bằng 1. Trong quá trình huấn luyện mô hình (cụ thể ở bước lan truyền ngược), chúng ta chỉ đụng tới những đơn vị không bị mask. Trong khi đó trong quá trình sử dụng mô hình, các vector trọng số $\mathbf{w}$ sẽ nhân thêm bởi p sao cho $\hat{\mathbf{w}} = p\mathbf{w}$.
Ngoài ra nhóm tác giả cũng tạo ra ràng buộc về chuẩn l2 của vector trọng số sử dụng l2 regularization, cụ thể hơn thì họ đã thay đổi giá trị của $\mathbf{w}$ sao cho $|\mathbf{w}|_2 = s$ nếu như $|\mathbf{w}|_2 > s$ sau bước gradient descent.
Tổng kết lại.
Đầu tiên các tác giả sử dụng mô hình tiền huấn luyện word2vec để lấy ra các đặc trưng từ. Sau đó họ sử dụng các filter có độ rộng khác nhau với mục đích mong muốn mô hình nắm bắt được nhiều ngữ cảnh trong câu hơn. Sau khi áp dụng phép convolution giữa input đầu vào với các filter khác nhau, họ thu được các feature map khác nhau, sau đó tiến hành max pooling để lấy ra feature mang tính đại diện nhất cho câu ứng với từng filter. Các units đó sẽ được nối với nhau bằng phép ghép để làm input cho một mạng MLP với hàm phi tuyến là hàm softmax để đưa đầu ra của mô hình thành các giá trị xác suất. Còn về cơ chế kiểm soát, họ áp dụng dropout cho mạng MLP và l2 regularization kết hợp với objective function.
Dưới đây là pseudocode mình làm, mọi người có thể tham khảo thêm nha.

Ứng dụng
Như vậy là giờ mọi người đã hiểu cách mà mô hình này hoạt động. Vậy giờ chúng ta sẽ đưa nó vào thực tiễn để xem đối với các bài toán NLP (cụ thể là bài toán phân tích cảm xúc) thì mô hình của chúng ta hoạt động ra sao. Mọi người có thể bấm vào đây để truy cập vào code của ứng dụng này.
!!clarify!!: Phần ứng dụng này sẽ không sử dụng các vector chữ được lấy từ mô hình ngôn ngữ học không giám sát như những gì mà chúng ta bàn luận ở trên, lần này chúng ta sẽ thật sự lấy ngẫu nhiên các giá trị trong mỗi phần tử của vector rồi các giá trị này sẽ được điều chỉnh thông qua quá trình huấn luyện… Nên là, đúng vậy, làm lại từ đầu tới đuôi luôn 💩
Về bộ dữ liệu, thì mình sử dụng một phần của bộ dữ liệu Amazon Reviews for Sentiment Analysis. Cụ thể hơn thì mình chỉ lấy 40.000 bản ghi cho tập huấn luyện và đâu đó khoảng 1000 bản ghi cho tập kiểm tra. Lưu ý ở đây là mình chỉ lấy mẫu thôi nha, chứ nếu mọi người tải bộ đó về mà chạy trên máy local mà yếu yếu hoặc sử dụng google colab bản bình thường thì nội việc lưu data trong bộ nhớ cũng rất tốn kém á. Bên cạnh đó thì bộ dữ liệu này đã được tiền xử lí từ trước rồi mình mới đẩy lên drive (các bước xử lí như loại bỏ nhãn xấu, v.v… cũng có nhiều hướng tiếp cận mới mẻ mà có dịp thì mình sẽ chia sẻ thêm ). Và để cho đơn giản hơn thì bộ dữ liệu này đang là bộ dữ liệu cân bằng (tỷ lệ nhãn của 2 lớp là bằng nhau trên cả tập huấn luyện và tập kiểm thử). Như 2 hình dưới đây:
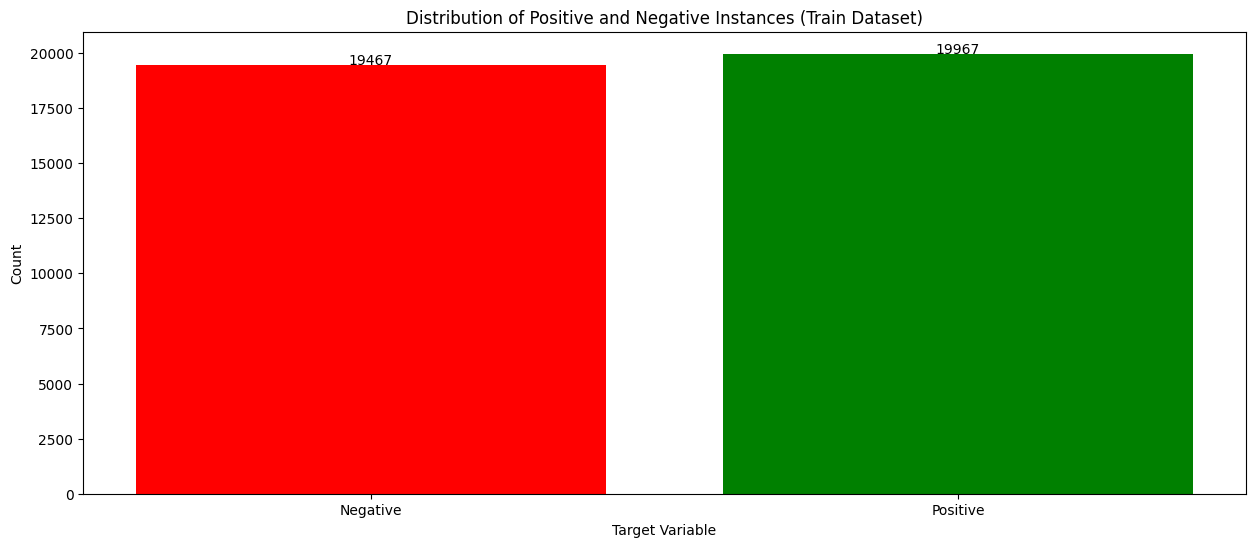
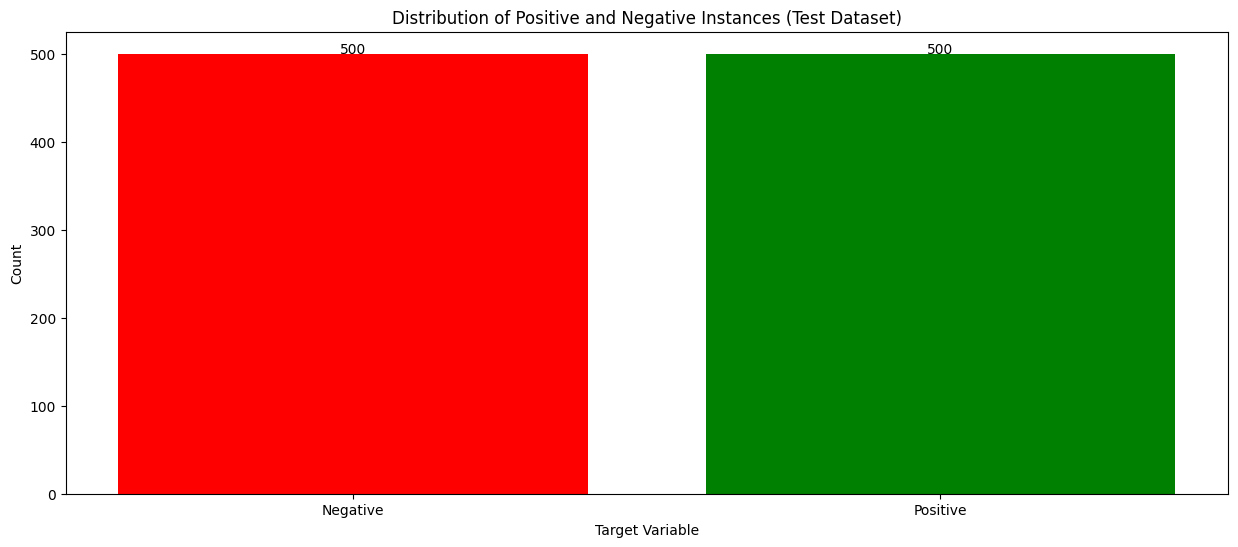
Về mô hình thì mình tham khảo trong repository này. Repository này được cấu trúc dễ đọc, dễ nắm bắt, nếu có thời gian thì mọi người nên clone về máy xong chạy local cũng ok, nói chung là check it out and give the author a star !!!. Dưới đây là toàn bộ mô hình:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
class textCNN(nn.Module):
def __init__(self, param):
super(textCNN, self).__init__()
ci = 1 # input chanel size
kernel_num = param['kernel_num'] # output chanel size
kernel_size = param['kernel_size']
vocab_size = param['vocab_size']
embed_dim = param['embed_dim']
dropout = param['dropout']
class_num = param['class_num']
self.param = param
self.embed = nn.Embedding(vocab_size, embed_dim, padding_idx=1)
self.conv11 = nn.Conv2d(ci, kernel_num, (kernel_size[0], embed_dim))
self.conv12 = nn.Conv2d(ci, kernel_num, (kernel_size[1], embed_dim))
self.conv13 = nn.Conv2d(ci, kernel_num, (kernel_size[2], embed_dim))
self.dropout = nn.Dropout(dropout)
self.fc1 = nn.Linear(len(kernel_size) * kernel_num, class_num)
def init_embed(self, embed_matrix):
self.embed.weight = nn.Parameter(torch.Tensor(embed_matrix))
@staticmethod
def conv_and_pool(x, conv):
# x: (batch, 1, sentence_length, )
x = conv(x)
# x: (batch, kernel_num, H_out, 1)
x = F.relu(x.squeeze(3))
# x: (batch, kernel_num, H_out)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
# (batch, kernel_num)
return x
def forward(self, x):
# x: (batch, sentence_length)
x = self.embed(x)
# x: (batch, sentence_length, embed_dim)
# TODO init embed matrix with pre-trained
x = x.unsqueeze(1)
# x: (batch, 1, sentence_length, embed_dim)
x1 = self.conv_and_pool(x, self.conv11) # (batch, kernel_num)
x2 = self.conv_and_pool(x, self.conv12) # (batch, kernel_num)
x3 = self.conv_and_pool(x, self.conv13) # (batch, kernel_num)
x = torch.cat((x1, x2, x3), 1) # (batch, 3 * kernel_num)
x = self.dropout(x)
logit = F.log_softmax(self.fc1(x), dim=1)
return logit
def init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
Còn dưới đây là các tham số mà mọi người có thể tinh chỉnh để mô hình đạt kết quả tốt hơn:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
textCNN_param = {
'vocab_size': 10000,
'embed_dim': 256,
'class_num': 2,
"kernel_num": 16,
"kernel_size": [3, 4, 5],
"dropout": 0.5,
}
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = textCNN(textCNN_param)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.00005)
num_epochs = 50
save_model = './model'
os.makedirs(save_model, exist_ok = True)
model_name = 'model_TextCNN'
Và sau khi chạy mô hình với các tham số ở trên (sử dụng GPU T4 free của google colab 😁✌️) thì có được kết quả như hình dưới đây (mô hình này chạy cũng nhanh lắm á mọi người, 50 epochs train vèo 1 phát cỡ 5-10 phút là xong rồi).
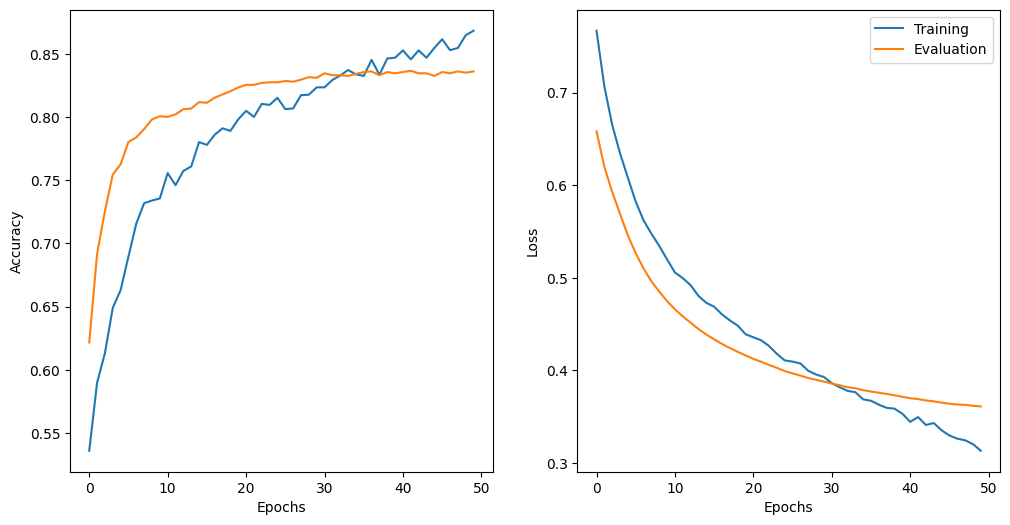
Một điểm đáng lưu ý là các siêu tham số mình chọn là mình chọn ngẫu nhiên thôi, nhưng kết quả của mô hình thì vẫn rất tốt. Tuy nhiên từ epoch thứ 30 trở đi là cái đường màu cam bắt đầu đi ngang rồi (nói dễ hiểu là mô hình chỉ làm được tới đó thôi), nên để tránh lãng phí tài nguyên tính toán thì mọi người nên thử thêm các phương pháp như early stopping để tối ưu chi phí huấn luyện mô hình.
Ưu và nhược điểm
Sau khi nghiên cứu cũng như ứng dụng mô hình cho một bộ dữ liệu thực tế thì mình sẽ cùng bàn luận về ưu và nhược điểm của mô hình này.
- Ưu điểm:
- Chi phí tính toán thấp: Các phép tích chập trong các mạng CNN được ưa chuộng một phần bởi vì chúng có ít tham số.
- Xử lí tốt các vùng cục bộ: Các vùng cục bộ ở đây có thể hiểu là các chữ nằm gần gần nhau như là một đoạn ngắn hoặc là n-grams. Điều này có thể được giải thích bởi phép tích chập, phép mà áp một cái filter vào một đoạn các chữ gần nhau để đưa ra các cấu trúc cục bộ có ý nghĩa.
- Nhược điểm:
- Kém trong việc nắm bắt thông tin toàn cục (global structure): Không như khi mình xử lí dữ liệu dạng ảnh thì các cấu trúc cục bộ rất quan trọng và có sự liên quan chặt chẽ với nhau. Điều này cũng là đúng khi chúng ta xét trong ngữ cảnh là câu từ. Tuy nhiên cũng có rất nhiều trường hợp mà các từ dù nằm xa nhau (hay nói cách khác là chúng không nằm gần nhau trong một vùng lân cận) vẫn gây ảnh hưởng mạnh đến ý nghĩa của câu. Đây là điều khiến cho mô hình này hoạt động không tốt nếu như chúng ta có những câu quá dài mà những chữ dù nằm xa nhau vẫn gây ảnh hưởng lên nhau.
Về sơ bộ thì đó là những ưu nhược điểm mà mình thấy trong thuật toán này, mọi người có thể nghiên cứu thêm để cùng bàn luận về vấn đề này trong tương lai.
Thảo luận thêm
Trong phạm vi bài nghiên cứu.
Trong phạm vi của bài nghiên cứu, nhóm tác giả có đưa ra vài một vài thảo luận chính mà mình sẽ đề cập ở phần dưới đây:
Multichannel vs Single Channel Models: Nhóm tác giả tin rằng nếu chúng ta sử dụng một mô hình nhiều kênh hơn thì sẽ tránh tình trạng mô hình gặp vấn đề overfitting, do đó mà hoạt động tốt hơn mô hình đơn kênh, và điều này sẽ càng được thể hiện rõ nếu như chúng ta cho mô hình chạy trên một tập dữ liệu nhỏ. Tuy nhiên kết quả của mô hình thì lại không như mong muốn (cụ thể hơn là nó bị lẫn lộn, do đó mà không đi tới kết luận cái nào tốt hơn được). Do đó mà một hướng tiếp cận có vẻ hợp lí hơn là tập trung kiểm soát quá trình fine-tuning. Giờ lấy ví dụ như thay vì mình sử dụng 2 kênh đầu vào, mỗi kênh có kích thước là
n x k, ví dụ như10 x 128, thì thay vì sử dụng 2 kênh như vậy, mình chỉ cần sử dụng 1 kênh thôi và kênh đó sẽ được biểu diễn bằng một mà trận có kích thước khác lớn hơn, ví dụ như10 x 256.Static vs Non-static representation: Một điểm chung thú vị của việc chúng ta sử dụng multichannel model (mô hình đa kênh) và singlechannel model (mô hình đơn kênh) đó chính là việc chúng đều có thể tinh chỉnh non-static channel (các kênh không tĩnh) sao cho nó hoạt động tốt nhất ở cái task mà chúng ta giao cho nó. Và nhân đây, một điều thú vị khác mà mình muốn đề cập đến chính là về việc biểu diễn từ dưới dạng vector. Chúng ta có nhận xét rằng một biểu diễn từ dưới dạng vector tốt là một biểu diễn thực tế của từ ngoài đời sống. Tuy nhiên một mô hình nào đó thì sẽ chỉ nhận một tập dữ liệu huấn luyện nào đó thôi, và khá chắc chắn là tập huấn luyện đó sẽ không thể nào phản ánh tất cả các ý nghĩa của từ ngoài đời thật. Do đó mà dữ liệu đầu vào cũng rất quan trọng, nếu ta cần các vector từ biểu diễn tốt công việc mà chúng ta giao thì chúng ta cũng cần đảm bảo rằng dữ liệu đầu vào là hoàn toàn phù hợp cho mô hình để học.
Ngoài phạm vi bài nghiên cứu.
Không chỉ trong khuôn khổ bài này mà ta thấy được sức mạnh của CNN trong việc xử lí dữ liệu văn bản. Có một vài bài nghiên cứ khác cũng đã đào sâu hơn, cho ta thấy thêm nhiều góc nhìn mới của mô hình này như bài “What Does a TextCNN Learn?”. Trong bài này, nhóm tác giả đưa ra các kết luận như sau:
- Các filter học các đặc trưng về nhãn: Các filter trong TextCNN có khả năng học các đặc điểm liên quan đến các nhãn được sử dụng để phân loại văn bản.
- Một số filter có tính tương đồng: Một số filter trong mạng có thể học các đặc trưng tương tự nhau, cho thấy sự trùng lặp trong việc trích xuất thông tin.
- Một số filter học các đặc trưng chung của các lớp khác nhau: Các filter cũng có thể học các đặc trưng chung cho các lớp khác nhau, giúp mô hình tổng quát hóa tốt hơn.
- Độ sâu của lớp ảnh hưởng đến các đặc trưng được học: Số lượng lớp trong mạng TextCNN có tác động đến mức độ phức tạp và sự trừu tượng của các đặc trưng được học.
Ngoài ra cũng có một vài bài cải thiện khác nhằm tăng độ chính xác của thuật toán như bài “A combination of TEXTCNN model and Bayesian classifier for microblog sentiment analysis”. Trong bài này, các tác giả không sử dụng các phương pháp embedding truyền thống, thay vào đó sử dụng mô hình ELMo để tạo các vector từ và sử dụng mạng LSTM 2 chiều để học đặc trưng từ. Còn về cấu trúc mô hình, bên cạnh những cái thay đổi về lớp embedding như vừa nêu, thì người ta chỉ đổi cái lớp fully connected sang thành cái Naive Bayes Classifier.
Sơ sơ thì đó là một vài việc mà người ta đã làm để phân tích và cải thiện kết quả của thuật toán, có thể có thêm nhiều mô hình khác cũng hay ho mà mình chưa biết, nên nếu có dịp thì mong được chia sẻ thêm với mọi người 😻
Trao đổi thêm.
Nếu có khúc mắc hay cần thảo luận thêm về vấn đề gì thì mọi người có thể liên hệ với mình qua email nha: tommyquanglowkey2011@gmail.com
Cheers🥂