Paper Explained 3: Masked Autoencoders Are Scalable Vision Learners
“Mask” aka 👺 là một kĩ thuật được ưa chuộng trong lĩnh vực NLP. Nó hoạt động bằng cách che đi một phần trong dữ liệu, rồi đoán cái phần bị che đó dựa vào những cái không bị che 🤨👌. Mục tiêu của nó đơn giản là để mô hình học được các biểu diễn chung trong dữ liệu, bất kể ngữ cảnh cụ thể. Vậy còn đối với dữ liệu 🖼️ thì cái này xài sao, giờ mình tìm hiểu trong bài này nhế !!! 💪.
Giới thiệu
Ngày nay mấy mô hình Deep Learning đã trở nên quá là mạnh cũng như là cái khả năng của nó là rất lớn, kết hợp với việc phần cứng giờ mạnh hơn và chuyên dụng hơn cho các bài toán liên quan đến AI làm cho việc con người train mô hình như là diều gặp gió 🪁🍃.
Bên lề xíu thì đây là dự đoán cho thị trường phần cứng cho AI từ năm 2022 cho tới năm 2030.
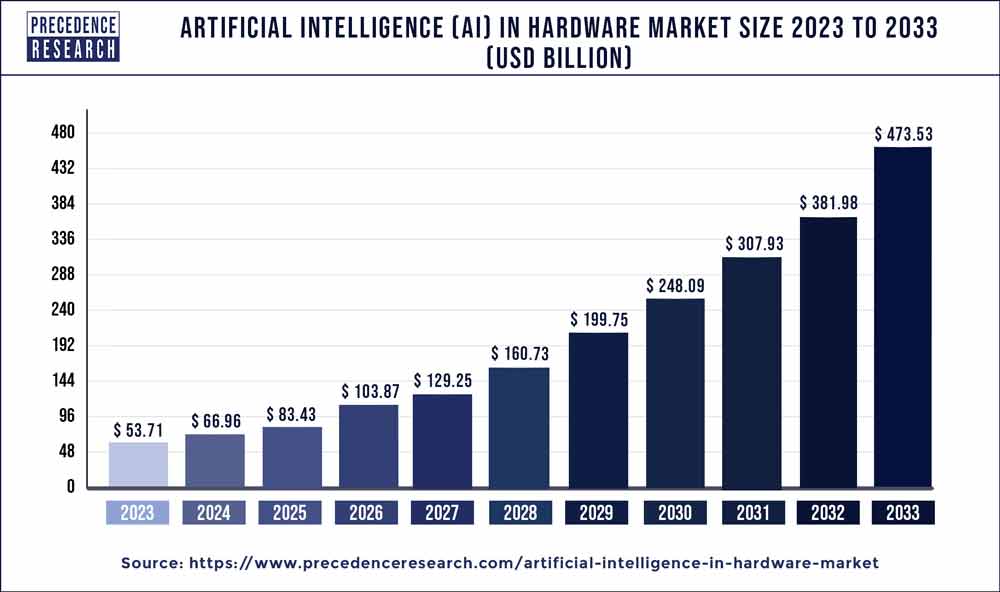
Đó, nói chung là rất khủng. Nhưng mà ae thử nghỉ, giờ cái gì cũng to ra, kiểu như ae đang tuổi ăn tuổi lớn đi, khẩu phần ăn của ae phải nhiều hơn đúng kh ? 🤔 (rõ ràng luôn). Thì mấy cái model này cũng v, giờ mô hình lớn hơn cần nhiều data hơn, kiểu kiểu vậy đó. Trước đó train 1M ảnh còn khó khăn chứ giờ ae train cả chục M ảnh trong phòng cũng daijoubu thoi. Nhưng mà vấn đề nè ae: 🥹 ? Đào đâu ra data giờ ní ? 🥹
Khó trả lời liền đúng kh ae =)))))))))))). Để cho ae có cái nhìn cụ thể hơn về cái thị trường cũng gọi là 🤑🫰💵💶💷 thì dưới đây là cái hình (nói chung từ năm 2019 lận) dự đoán tăng trưởng tới 2025.

Đó, nói chung là hao tiền. Nhưng mà có cách nào khác để counter không? Câu trả lời là YES. Cái sự háu ăn của các model ngày nay có thể được giải quyết bằng phương pháp ✨self-supervised learning✨.
Cụ thể hơn thì có một cái task cụ thể trong NLP, đó là Masking Task, thì cái này đơn giản là nó huấn luyện mô hình bằng cách dự đoán các từ bị thiếu trong câu 👺🔮. Cụ thể hơn thì đầu tiên nó tiến hành che vài từ trong câu (đương nhiên là ít từ thôi nhé, chứ che nhiều quá thì không dự đoán được👽👌) và sử dụng các từ còn lại để đoán ra từ đó. Như cái hình ở dưới này là một cái ví dụ cụ thể:
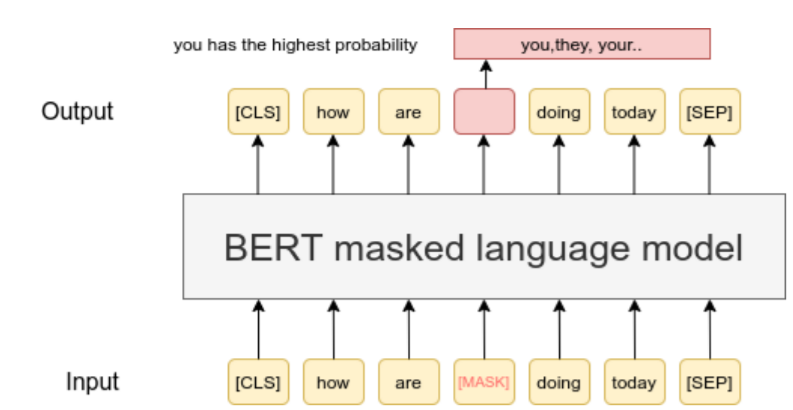
Thì cái lợi ích của cái việc này là nó cho phép mô hình học các từ dựa trên ngữ cảnh (đương nhiên là không cần label 🥂). Câu hỏi là đối với hình ảnh, mình làm vậy được không? Nói luôn là được nhé! Giờ mình làm cái này nè ae, paper gốc mọi người có thể đọc ở đây nha!
Trong cái bài nghiên cứu này, các tác giả đặt ra câu hỏi: Điều gì làm cho masked autoencoder khác biệt giữa dữ liệu dạng chữ và dữ liệu dạng ảnh?. Và họ trả lời câu hỏi này bằng việc đặt ra 3 vấn đề chính:
Khác biệt trong cấu trúc mô hình🏗️: Thông thường, khi sử dụng dữ liệu cho dạng ảnh thì người ta dùng mấy cấu trúc CNN, còn cho dữ liệu văn bản thì người ta dùng RNN hoặc là Transformer. Cái vấn đề mấu chốt khiến cho ae không áp dụng cái masking thông thường cho mấy mạng CNN là bởi vì cái phép tích chập nó chỉ hoạt động ok với những cái grid thông thường chứ nó không có xác định được cái nào bị mask và phải deal sao với cái cell bị mask trong cái grid đó. ae thấy vấn đề chưa? Nhưng mà thanks to cấu trúc Transformer, cụ thể là mô hình ViT, mà cái này không còn là chướng ngại nữa. Nên tạm thời một vấn đề được giải quyết.
Khác biệt trong mật độ thông tin🤨: Thì cái mật độ thông tin trong từng loại dữ liệu là khác nhau. ae tưởng tượng ngôn ngữ là do con người quy định, do đó trong văn bản, nó mang tính ngữ nghĩa cao cũng như mật độ thông tin rất dày đặc, hầu hết mọi câu ae thốt ra đều dính dính với nhau, chứ không phải kiểu câu dài 4 chữ mà 4 chữ chả liên quan gì nhau =))))))))))) đọc nó cứ cấn cấn. Hình ảnh thì ngược lại, hình ảnh tồn tại trong tự nhiên, con người không có ‘quy ra hình ảnh’ được, ngoài ra hình ảnh còn là loại dữ liệu có tương quan không gian cao (này cụm gốc là heavy spatial redundancy và đề cập đến mối liên hệ mật thiết giữa các điểm ảnh trong không gian). Do đó mà đối với hình ảnh, bị hụt một vài chỗ thôi thì vẫn dùng các dữ liệu lân cận để tái cấu trúc lại phần bị khuyết đó chỉ cần mô hình hiểu được một vài bản chất cơ bản của hình ảnh như là đối tượng trong ảnh, khung cảnh trong ảnh, v.v… Mà như vậy thì nếu như chỉ che một xíu như bên dữ liệu văn bản thôi thì dễ quá 🤨👌👎. Nên nhóm tác giả có đề xuất mình sẽ mask phần lớn ảnh, có khi mask tới 85% ảnh luôn, không vấn đề gì cạ! 💯. Có 2 mục đích chính: Giảm thiểu dư thừa trong tính toán (chứ che xíu thì dễ quá, tính chi nữa, với cả làm vậy thì phải tính toán rất nhiều mà hiệu quả mang lại rất ít) và Tạo ra một task đủ khó để hiểu nhiều hơn về tấm ảnh chứ không chỉ đơn giản là vài bản chất cơ bản của tấm ảnh (điều này ép cho mô hình phải học những cái khó hơn, từ đó làm tốt hơn).
Phần decoder: Có một sự đối lập trong phần decoder khi dùng để dự đoán cái mask cho dữ liệu ảnh và dữ liệu văn bản. Hiểu đơn giản thì đối với dữ liệu ảnh, phần này sẽ tái cấu trúc lại ở pixel-level, như vậy có thể thấy rằng các cái pixel được tái cấu trúc này có tính ngữ nghĩa thấp. Trong khi đó đối với dữ liệu văn bản thì khác, như nãy mình nói là văn bản là loại dữ liệu có tính ngữ nghĩa dày đặc, thì cái này từ được dữ đoán cũng phải có tính ngữ nghĩa cao.
Và từ những nhận xét trên mà nhóm tác giả đã đề xuất ra mô hình MAE (Masked AutoEncoder) để học các đặt trưng của ảnh. Với mô tả ngắn gọn (chi tiết vô sau) về mô hình. MAE sẽ che mấy cái patches từ cái ảnh đầu vào rồi tái cấu trúc nó ở pixel-level. Và không như những cái AE mà ae hay gặp, cái AE mà tác giả giới thiệu là một cấu trúc bất đối xứng (bất đối xứng trong AE có nghĩa là phần encoder và decoder có cái kích thước khác nhau). Trong khi phần encoder chỉ hoạt động đối với những phần không bị che thì phần decoder hoạt động luôn cả phần bị che lẫn khôgn bị che. Nói tóm gọn thì là như vậy, mình sẽ giải thích cụ thể hơn ở phần sau, trước mắt mọi người có thể xem cái hình này để nắm được cái mô hình này trông ra sao:
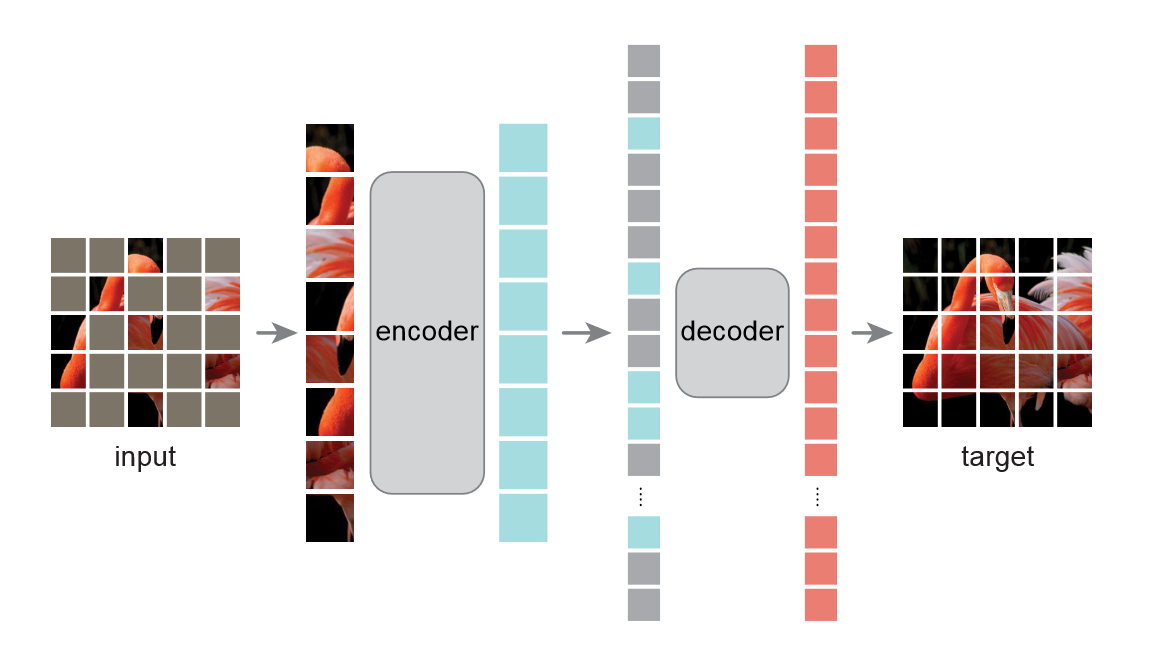
Và khi mình nói tới việc tái cấu trúc lại hình thì là như sau:

Đó, trước mắt thì nó đơn giản vậy thôi à, để cụ thể hơn thì mình qua phần mô hình sau hen !👽
REFERENCES
(2) https://www.lightly.ai/post/ai-human-bottleneck
(4) https://arxiv.org/pdf/2111.06377
Các khái niệm liên quan
Masked Language Modeling (Mô hình ngôn ngữ học từ ngữ cảnh)
Cái MLM là một trong các kĩ thuật NLP rất thành công trong việc pre-trained mấy cái mô hình deep learning. Cái mô hình BERT mà có thể mấy bạn quen thuộc cũng sử dụng kĩ thuật này để tiến hành pre-trained. Và cũng có những bài nghiên cứu đã cho thấy rằng cái phương pháp này là siêu hiệu quả khi mà mình scale nó lên như bài này. Bên cạnh đó khi thực nghiệm thì cũng có rất nhiều ứng dụng khi áp dụng pretrained model theo phương pháp này cho ra các kết quả rất tốt.
Thì cái này như mình đề cập ở trên, là mình sẽ che bớt vài từ trong câu và dùng những từ còn lại để dự đoán những từ đó, và tất nhiên xét về mặt ngữ nghĩa thì các từ này rất có ý nghĩa bởi vì tính chất của câu mà mình đề cập lúc nãy.
Ok, vậy là giờ chúng ta đã hiểu cái MLM là nó làm gì rồi đúng kh, nhưng mà cụ thể nó làm ra sao thì mọi người có thể đọc thêm ở bài này để biết thêm chi tiết nhế. Nếu được thì chắc mình sẽ lên một bài nói về BERT và nếu được thi chắc code lại cái bản lightweight của nó cũng được.
Autoencoder (Bộ tự mã hóa)
Cái autoencoder này là một phương pháp cổ điển để học các biểu diễn của dữ liệu đầu vào. Hầu như bộ autoencoder nào cũng sẽ gồm 2 phần chính (mình chưa thấy cái nào có hơn 2 bộ 😐) đó là phần encoder giúp ánh xạ biểu diễn của dữ liệu đầu vào sang một cái không gian (thường là có số chiều nhỏ hơn) gọi là ‘latent space’ và từ cái không gian này, decoder sẽ cố gắng ánh xạ nó về không gian ban đầu (nói cụ thể hơn là cái decoder sẽ cố gắng tái cấu trúc lại dữ liệu đầu vào từ cái vector đại diện dữ liệu đầu vào đó trong cái latent space). Và bộ này thông thường sẽ nhìn như sau:
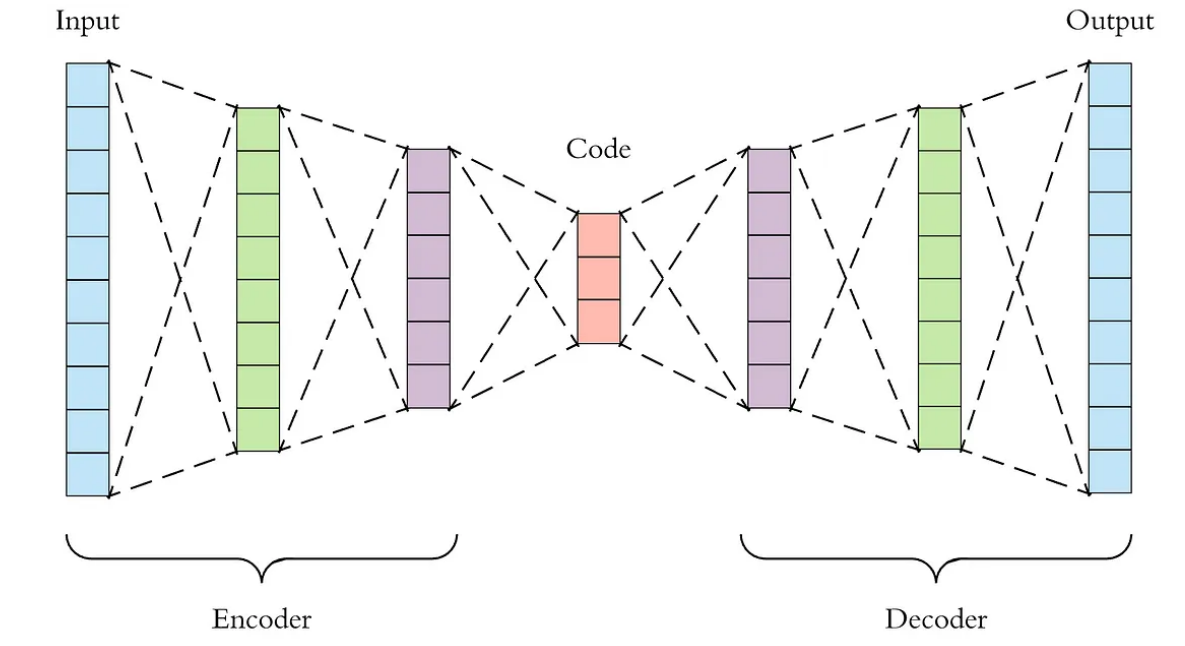
Một phần nhỏ hơn của lớp autoencoder đó là DAE (Denoising autoencoder). Những cái mô hình có cấu trúc DAE thường sẽ nhận vào một tín hiệu đầu vào đã bị nhiễu (paper dùng từ corrupt), sau đó cho vào latent space, sau đó decoder sẽ cố gắng tái cấu trúc lại tín hiệu đầu vào không bị nhiễu. Và nó cũng có nhiều hướng tiếp cận sử dụng cái DAE này lắm mng, kiểu như đối với dữ liệu dạng ảnh, người ta có thể rút bớt 1 channel, hoặc là xóa đi vài pixel trong ảnh, v.v…. Nói chung cái mô hình MAE mà hôm nay chúng mình tìm hiểu có thể xem như là một phần của cái cấu trúc DAE.
Masked Image Encoding
Cái này nghe thì có vẻ hao hao cái MLM ở trên đó, nhưng để cụ thể hơn, thì cái phương pháp này sẽ học được những biểu diễn từ cái ảnh bị hỏng (corrupt) do masking. Hoặc là thêm nhiễu vào ảnh, hoặc là inpaint ảnh rồi dùng CNN để khôi phục, v.v… Nói chung là nhiều mà mình cũng chưa tìm hiểu hết đống này.
Self-supervised learning (Học tự giám sát)
Gọi là tự giám sát bởi vì các mô hình sử dụng phương pháp này sẽ tự tạo ra các “giám sát” riêng của mình bằng cách tìm kiếm các cấu trúc và mối quan hệ ẩn trong dữ liệu để học được các biểu diễn có ích của dữ liệu. Và cái nhược điểm của nó như đầu bài viết mình có đề cập đó là không tốn tiền thuê nhân công gắn nhãn thủ công. Nhưng mà rõ ràng là nếu làm vậy thì performance của nó không có đá vô đầu cái thằng supervised learning được. Nên là phải đánh đổi thôi.
Tuy nhiên cách tiếp cận này rất là hữu dụng nếu ae muốn giải quyết một cái downstream task nào đó. Bởi vì sau khi đã qua nhiều cái pretext task như next sentence prediction hay là MLM hay là tự fill kênh màu hay là gì gì đấy thì model đã học được biểu diễn của dữ liệu rất tốt rồi.
REFERENCES
(1) https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html
(2) https://towardsdatascience.com/masked-language-modelling-with-bert-7d49793e5d2c
Tổng quan mô hình
Mô hình MAE mà tác giả đề cập là một biến thể hay nói đúng hơn là thuộc cấu trúc DAE (denoising autoencoder) mình có đề cập lúc nãy. Và cũng như bao nhiêu cấu trúc AE khác thôi, phần encoder sẽ ánh xạ tín hiệu đầu vào (trong trường hợp này là một biểu diễn thưa của hình ảnh do chúng ta đã thực hiện masking rồi), mà cụ thể hơn thì trong MAE, phần encoder sẽ chỉ tính toán dựa trên các phần không bị mask thôi (tức là các phần mà có thể quan sát được). Và rồi phần decoder sẽ cố gắng tái cấu trúc tín hiệu ban đầu (biểu diễn hình ảnh hoàn chỉnh lúc chưa bị masking) từ cái latent space đó.
Masking
Trong paper này, masking của các patch ảnh (theo ngôn ngữ của ViT) được set ở một tỷ lệ rất nhanh, trong paper nó lấy là 85%, nói nôm na, 85% của tấm ảnh sẽ bị che đi, nhiệm vụ của 15% pixel còn lại trong ảnh là cố gắng tái cấu trúc lại 85% đó. Nghe thì nó buồn cười, nhưng mà nó lại work well =))))))))))))))))).
MAE encoder
MAE decoder
Objective function và Optimizer
Ứng dụng mô hình
Thảo luận thêm và nhận xét
Trong lúc viết bài này thì mình suy nghĩ vu vơ, giờ lấy ví dụ như mọi người đang có một cái prompt với một cái ảnh và cái prompt đang tả cái ảnh đó đi. Có cái task nào đó kiểu như mọi người đang có cái hình con nguồi đứng cạnh con chó, và có cái prompt ghi i xì vậy luôn, rồi mọi người mask con chó trong tấm hình đi, rồi mọi người từ cái prompt, cố gắng reconstruct lại con chó đó. Hoặc là mọi người có thể làm cái NER task để enhance cái representation của câu với ảnh 😐😐😐might work tho