Paper Explained 2: Pay Attention to MLPs
📣 Attention Attention Attention, attention này attention kia, quá nhiều attention. 😅 Trong bài viết này chúng ta sẽ cùng thảo luận về một cách khác cũng đáng nhận được attention, mặc dù không phải attention. 🤔 Chủ đề hôm này của chúng ta sẽ bàn về MLP (cụ thể hơn thì là một biến thể của mạng MLP truyền thống) nói chung và gMLP nói riêng (Highlight của biến thể này là Spatial Gating Unit - Một đơn vị để kiểm soát thông tin). 🎯 Bài này khá hay, cùng đọc nhế !!! 📚🎉
Giới thiệu.
!! NOTICE !! Chữ kiến trúc với chữ mô hình nó hơi nhạy cảm mọi người, nên trong bài này, mình nói kiến trúc là nói chung, còn mô hình là nói cụ thể, chỉ đích danh mô hình đó luôn. z thui, cheers
Các bạn mà có hay cập nhật các thông tin về mấy cái mô hình ngôn ngữ lớn (LLM) như mấy cái Mistral, LLaMa, v.v… thì chắc các bạn cũng đã biết cái phần cốt lõi của mấy mô hình khủng này là kiến trúc Transformer (mà cụ thể hơn là cơ chế attention của nó).
Những cái kiến trúc của Transformer bao gồm 2 thành phần chính là đó là một cái kiến trúc recurrent-free (do đó mà nó cho phép tính cái representation của các tokens một cách song song) và khối multi-head self-attention cho phép đa dạng và tổng hợp thông tin giữa các token với nhau.
Vậy câu hỏi đặt ra ở đây là: “Cái khối attention đó có cần thiết không?”. Bởi vì xét theo một mặt nào đó, cơ chế attention có một cái inductive bias đó là tương tác giữa các token nên được tham số một cách dynamic dựa trên biểu diễn đầu vào, tức là các cái representation có thể thay đổi dựa trên input của mô hình. Nhưng xét theo mặt khác, dựa vào Universal Approximation Theorem, bất kì cấu trúc MLP nào với cũng có thể xấp xỉ một hàm nào đó với tham số cố định. Và từ những suy nghĩ trên, mình có thể chuyển câu hỏi vừa đặt ra sang một câu khác cũng khá tương tự: “Điều gì đóng góp tới thành công của mô hình hơn? Một cái inductive bias yếu trong cơ chế attention hay khả năng xấp xỉ bất kỳ hàm toán học nào của các mạng Neural?”
Thì bài nghiên cứu của các tác giả, bên cạnh việc trả lời câu hỏi ở trên, tác giả mới giới thiệu một mô hình mới gọi là gMLP bởi vì nó được tạo ra từ kiến trúc MLP và một đơn vị cổng (gating unit).
Và spoil trước, nó hiệu quả.
Inductive bias (Thiên kiến quy nạp)
Để dễ hiểu hơn thì mọi người tưởng tượng: Trước tới giờ mọi người chỉ thấy một đàn thiên nga đang bơi trong một cái hồ gần nhà thôi, và đây là nơi duy nhất trong đời mà mọi người có thể quan sát mấy con thiên nga này. Một đống giả thuyết về mấy con thiên nga này mà các bạn có thể đặt ra như sau: “Thiên nga là loài có màu trắng”, “Thiên nga chỉ biết bơi”, “Thiên nga không biết bay”, “Thiên nga đen không tồn tại”,v.v… Nói chung là mọi người có đưa ra giả thuyết nào cũng được, do đó mà có vô số giả thuyết có thể được đưa ra, đúng hay sai là chuyện khác.

Theo lý thuyết, không gian giả thuyết là vô tận (tức là mọi người nghĩ ra bao nhiêu cái giả thuyết cũng được, không giới hạn, đúng sai bàn sau). Cái inductive bias có thể được hiểu như là các giả thuyết được ưu tiên hơn trong không gian giả thuyết. Lấy ví dụ như mấy bài toán như hồi quy tuyến tính, mọi người đang giả định tồn tại mối quan hệ tuyến tính giữa các điểm dữ liệu, và bằng cái giả định này, mọi người đồng thời giới hạn không gian giả thuyết xuống còn mối quan hệ tuyến tính.
Vậy trong khuôn khổ của machine learning thì điều này là sao? Mọi người đang có đa dạng dữ liệu (ảnh, chữ, tín hiệu, v.v…) và vô vàn loại mô hình khác nhau (tích chập, hồi quy, v.v…) và mỗi mô hình khác nhau này đều có một cái inductive bias để nó hoạt động tốt khác nhau. Ví dụ như là các mạng CNN được xây dựng dựa trên giả thuyết các điểm pixel nằm gần nhau thì có liên quan tới nhau và mô hình nên học được cái sự liên quan này.
Và nhân vật chính của chúng ta là kiến trúc Transformer, mô hình này không có một cái inductive bias mạnh, do đó cho phép mô hình khái quát hóa tốt hơn khi nó được huấn luyện với nhiều dữ liệu hơn. Lí do đơn giản bởi vì kiến trúc Transformer không đặt ra các giả định về đầu vào của mô hình, mà nó sẽ học thông qua cơ chế attention để biết các đầu vào khác nhau ở các vị trí khác nhau tương tác như thế nào. Các bạn có thể xem thêm các cái giải thích của cái inductive bias này ở đây hoặc ở đây
The Universal Approximation Theorem
Có một bài viết hay nói về chủ đề này mà mọi người có thể theo dõi thêm, mình để link ở đây nha.
Nói đơn giản thì định lí này cho rằng một số lượng đếm được các neuron trong cái mạng neuron có thể xấp xỉ bất kì hàm liên tục nào với sự chính xác ở một mức độ nào đó (chấp nhận sai số) với một hàm kích hoạt như Sigmoid hay ReLU hay một hàm nào khác.
Cách mô hình hoạt động
Trước khi thảo luận thêm, trong bài báo gốc, người ta có dùng 2 từ mà lần đầu đọc mình cũng chưa hiểu rõ những cái đó là gì, để dễ cắt nghĩa hơn thì ở đây mình giải thích lun:
spatial: Mọi người cứ hiểu lúc mà nói cái axis = ‘spatial’, tức là người ta đang đề cập đến không gian dòng trong cái ma trận.
channel: Thường mọi người nghe cái channel này trong mấy cái dạng bài liên quan đến ảnh là nhiều, trong NLP, mà cụ thể trong bài này, khi nhắc tới axis = ‘channel’, tức là người ta đang đề cập đến không gian cột trong cái ma trận.
Lấy ví dụ như cái câu của mình đang được biểu diễn dưới dạng một ma trận có 50 dòng và 512 cột đi ha, thì có nghĩa cái axis = ‘spatial’ sẽ là cái trục liên quan đến không gian dòng, tức là liên quan đến số 50, còn nếu axis = ‘channel’ sẽ là cái trục liên quan đến không gian cột, tức liên quan đến con số 512, trong trường hợp mình vừa nêu, tức là mình đang có 512 channel.
Dưới đây là cấu trúc mô hình, mình sẽ phân tích cụ thể từng thành phần sau:
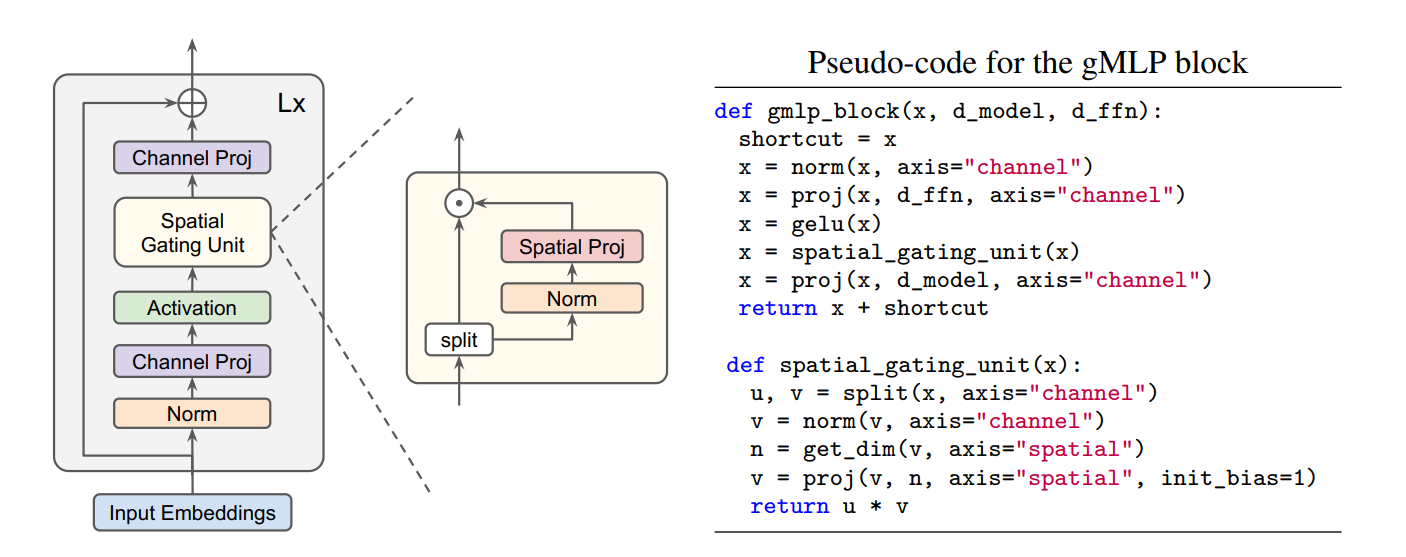
Mô hình gMLP này khá là cụ thể, như hình trên, mọi người có thể thấy rằng mô hình sẽ bao gồm một cái chồng gồm $L$ khối đè lên nhau với kích thước và cấu trúc như nhau và mỗi khối sẽ đưuọc định nghĩa như sau:
\[Z = \sigma(XU), \quad \tilde{Z} = s(Z), \quad Y = \tilde{Z}V\]Cái $Z$ với cái $Y$ về cơ bản là phép Channel Projection, còn cái $\tilde{Z}$ là cái Spatial Gating Unit, với điểm nhấn của nó là phép Spatial Projection.
Quan trọng nhất trong 3 cái công thức ở trên đó là cái ở giữa, chúng ta phải thiết kế làm sao mà $\tilde{Z}$ phản ánh được sự tương tác giữa những token trong câu, nói một cách khác là phải làm sao để $s(\cdot)$ cho phép biến đổi từ $Z$ sang $\tilde{Z}$ trở nên hữu dụng khi nó cho phép học được tương tác giữa các tokens trong câu.
Lưu ý rằng nếu $s(\cdot)$ là một hàm ánh xạ đồng nhất, cái biến đổi ở trên trở thành một cái FFN thông thường (mỗi tokens được xử lí độc lập với nhau và không liên quan với nhau). Do đó mà thiết kế $s(\cdot)$ sao cho nó học được tương tác giữa những token trong câu rất quan trọng đối với mô hình này. Và cách mà các tác giả đề xuất để xây dựng cái $s(\cdot)$ này là xem nó như một cái spatial depthwise convolution (không biết dịch sao 🤡)
Channel Projection
Hiểu đơn giản thì channel projection chỉ là một phép chiếu thôi mọi người, nếu mọi người ít sử dụng pytorch thì nó là cái torch.nn.Linear(in_features, out_features) á mọi người. Công thức toán của phép này là như sau:
Với x là ma trận đầu vào, A là ma trận giúp ánh xạ từ không gian có cái chiều đầu vào là in_features sang chiều out_features. Còn $b$ là bias
Nên là cái paper này nói cao siêu vậy chứ cái này đơn giản là cái MLP thôi à 🥹
Spatial Gating Unit
Spatial Gating Unit, hay gọi nhanh SGU là một khối cho phép mô hình gMLP này học được tương tácc giữa các token với nhau thông qua một phép chiếu khác bên trong khối này, phép chiếu này cũng đơn giản là một phép ánh xạ tuyến tính luôn mọi người. Nhưng không đơn giản như cái channel projection, cái này phía tác giả gọi cái khối đảm nhiệm việc này là spatial projection. Bên cạnh đó tác giả cũng đề cập thêm là cái layer này sẽ chứa một cái gọi là contraction operator (theo mình tìm hiểu thì cái này là một một hàm ánh xạ $T: V \mapsto V$ được định nghĩa bởi $T(v) = kv$ với $k \in \mathbb{R}$ sao cho $k < 1$). Và như những gì đã đề cập về việc đây là phép biến đổi tuyến tính thì nó có công thức như sau:
\[f_{W,b}(Z) = WZ + b\]Với $W \in \mathbb{R}^{n \times n}$ , trong đó n là chiều dài của câu như hồi nãy mình đề cập á mọi người. Như vậy $W$ sẽ là một ma trận vuông ánh xạ từ không gian n sang chính không gian n, còn $b$ thì là bias thôi.
Lấy ví dụ như nếu như cái câu của mình có 150 tokens như nãy đi ha, thì ma trận $W$ sẽ có kích thước là (150, 150). Và không như cơ chế self-attention có tính inductive bias yếu, do đó mà $W(Z)$ là không phải một biểu diễn linh hoạt dựa vào đầu vào $Z$, mà ma trận ánh xạ $W$ này sẽ độc lập khỏi biểu diễn đầu vào.
Như vậy mà cái layer $S(\cdot)$ sẽ được biểu diễn dưới dạng công thức như sau:
\[s(Z) = Z \odot f_{W,b}(Z)\]Với $\odot$ là phép nhân hamdard (ai không quen chữ này thì hiểu là phép nhân elemet-wise cũng được).
Thì khối này về cơ bản là xong rồi nha mọi người, tuy nhiên cần phải lưu ý thêm về một vài điều chỉnh của tác giả. Để cho quá trình huấn luyện model nó ổn định hơn, thì đầu tiên các tác giả đặt giá trị khởi tạo của ma trận $W$ là các giá trị xấp xỉ giá 0, trong khi đó đặt giá trị của $b$ thẳng bằng 1, điều này cũng đồng nghĩa với việc $f_{W,b} \approx \mathbf{1}$, điều này trực tiếp dẫn tới $s(Z) \approx Z$ ở giai đoạn đầu tiên của quá trình huấn luyện, đảm bảo rằng mỗi khối gMLP sẽ hoạt động như một cái FFN (tức là trong đó mỗi token được xử lí độc lập với nhau và mối quan hệ giữa các token đó sẽ được cập nhật thông qua quá trình huấn luyện). Và ngoài ra bằng việc chia ma trận $Z$ thành 2 nửa ($Z_1, Z_2$) thì tác giả thấy làm vậy nó thuận tiện hơn (chắc là theo thực nghiệm, mình không thấy tác giả đề cập gì về vụ này 😻), à mà chia 1 nửa ở đây là chia theo channel á nha, ví dụ như đầu vào Z của mình đang là (150, 512) thì lúc nãy mỗi cái $Z_1$, $Z_2$ sẽ có cái kích thước là (150, 256). Như vậy thì cái công thức ở trên có thể ghi lại như dưới đây:
\[s(Z) = Z_1 \odot f_{W,b}(Z_2)\]Thì như đã đề cập lúc nãy, ma trận $W$ xấp xỉ 0, thì mình sẽ cho các cái value này được lấy từ một cái Uniform Distriution với cái range gần 0 nhất có thể, và vẽ nó bằng heatmap thì nó ra được cái hình này:

Mục đích nằm ở ma trận vuông $W$ sẽ học được các tương tác có ý nghĩa giữa các token. Để hiểu rõ hơn nó là ra sao thì mọi người nhìn thử cái hình dưới đây:
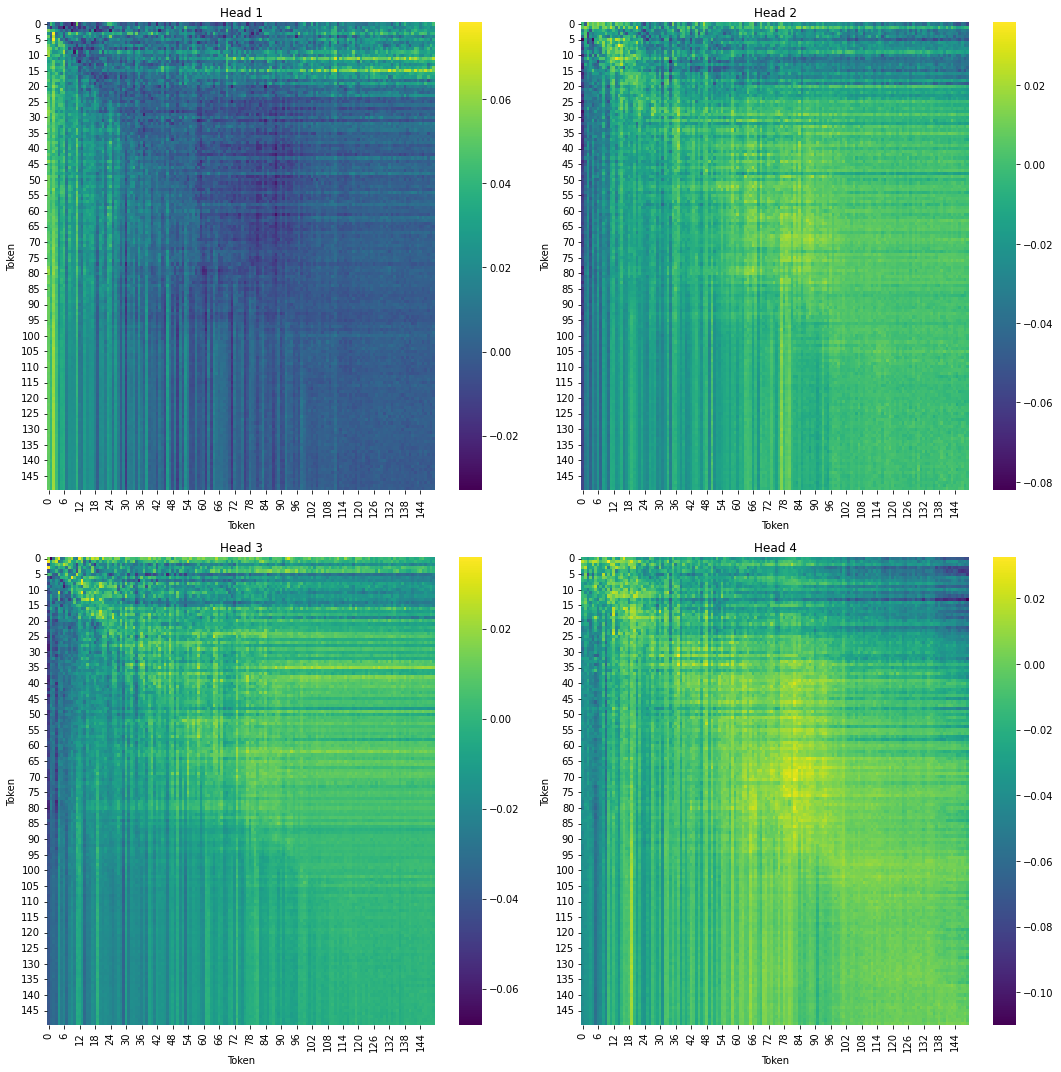
Trong lúc chạy code, mình có để cái head = 4 nên về cơ bản thì mình sẽ có 4 cái ma trận $W$ rồi có gì sau này mình gom 4 cái head vô thành 1 cái head là được. Thì về cơ bản, 4 cái head này là cố định, chứ nó không có dynamic như cái cơ chế attention.
Thì ở đây là đang sử dụng 4 head, về sau thì sẽ gộp lại làm 1 head thôi, đơn giản nhất mà ai cũng nghĩ tới khi gộp 4 head thành 1 head thì là sử dụng tính trung bình, cứ cộng cả 4 cái head lại xong rồi chia 4, thì ra được cái ma trận $W$ sau đây:
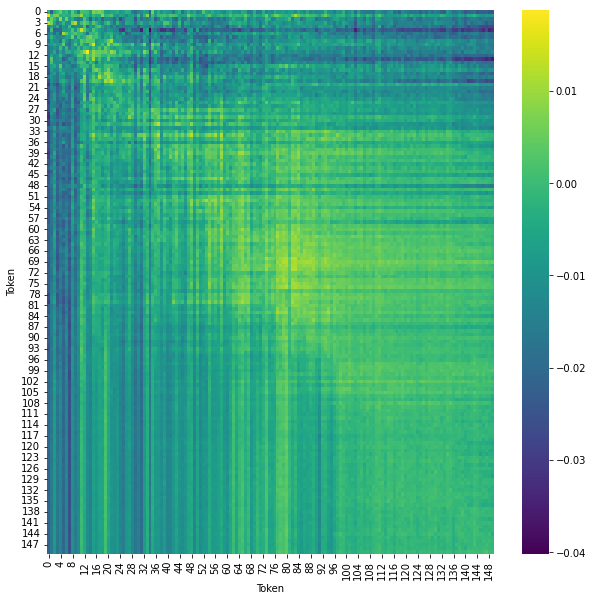
Ngoài ra bên phía tác giả cũng có kết hợp thêm cái cơ chế attention vô trong mấy cái khối này, thì họ được kết quả như dưới đây:
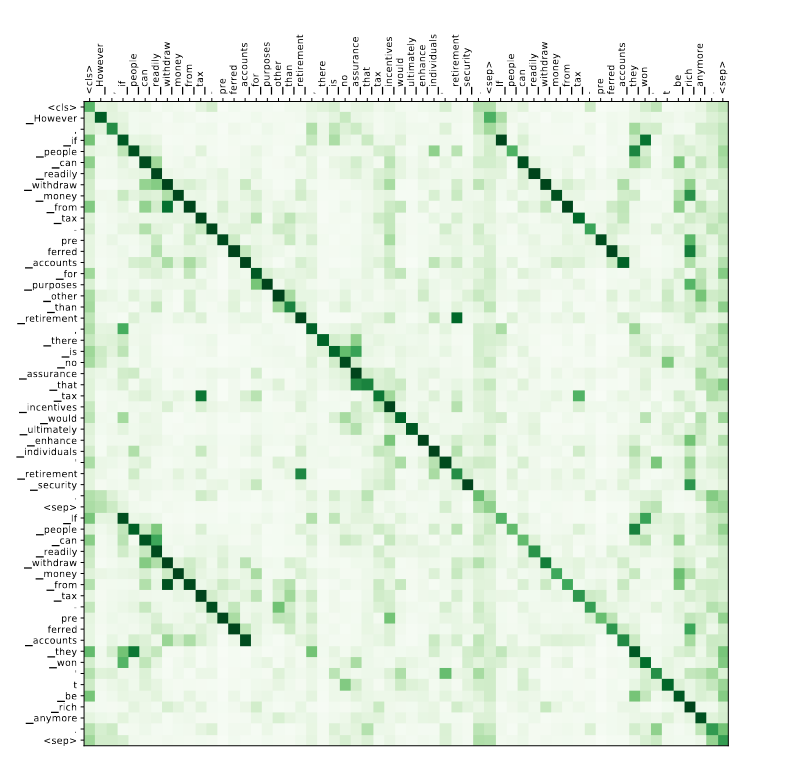
Toàn bộ cấu trúc mô hình
Biểu diễn đầu vào (a.k.a input embeddings) sẽ là một ma trận có kích thước $x \in \mathbb{R}^{n \times d}$ với $n$ là độ dài của câu và $d$ là chiều của vector biểu diễn.
Sau đó ma trận biểu diễn này sẽ được chuẩn hóa (cách thức chuẩn hóa sẽ là chuẩn hóa theo axis = ‘channel’). Chuẩn hóa ở đây sẽ là chuẩn hóa theo layer, nếu ai chưa sử dụng cái này trong pytorch thì nó là torch.nn.LayerNorm nha mọi người, về cơ bản thì công tức toán của cái này như sau:
Cái này mà giải thích nhanh thì nó kiểu như là giá trị đầu vào của tất cả neuron trong cùng một layer được chuẩn hóa cho từng diểm dữ liệu.
Và kế đến sau đó, ma trận được trả ra từ bước chuẩn hóa sẽ được chiếu qua một không gian khác. Bước chiếu này khá đơn giản thôi mọi người, cứ tưởng tượng nó là một hàm toán như kiểu $f: \mathbb{R}^{150 \times 512} \rightarrow \mathbb{R}^{150 \times 256}$, hiểu như vậy thì nó chính là phép nn.Linear() trong pytorch luôn.
Sau đó ma trận mới này sẽ đi qua một hàm kích hoạt nào đó, có thể là hàm ReLU hay GeLU hay gì gì đấy, như vậy thì ta có thể biểu diễn dưới công thức toán học từ sau bước normalize như sau:
\[Z = \sigma(XU)\]Với X là đầu vào, U là một ma trận cho phép ánh xạ X sang một không gian có số chiều khác, còn $\sigma$ là một hàm kích hoạt phi tuyến nào đó như nãy mình nói. Thì phần này chỉ là khúc Channel Projection thôi chứ không gì mới á ae.
Rồi cái $Z$ này sẽ đi qua cái Spatial Gating Unit ở trên rồi lại đi qua một cái Channel Projection nữa để nó về lại cùng chiều với cái d_model lúc đầu.
Và ở phía cuối cùng này, các token (trong trường hợp text) hoặc các patches (trong trường hợp ảnh) đã học được sự tương tác của nhau rồi, và như nãy mình nói á, cái ma trận $W$ là độc lập với cái đầu vào, nên là nó không có dynamic như cái cơ chế attention. Và hy vọng là ma trận này có thể xấp xỉ một hàm nào đó (theo như Universal Approximation Theorem).
Lúc này thì mọi người thêm cái đầu để làm classification hay là generation gì cũng được, lúc này thì tùy người thiết kế thôi
Ứng dụng
Cái này thì vô vàn ứng dụng luôn anh em, trong paper thì người ta ứng dụng cả trong Vision, cả trong NLP. Do post trước làm Text Classfication rồi nên post này mình miêu tả rõ hơn cái Image Classification ha, nhưng mà code mình có để trong github rồi, mọi người có thể tham khảo thêm ở đây.
Ở thời điểm đó, các tác giả thực hiện phân tích hiệu quả của gMLP trong lĩnh vực Computer Vision, cụ thể hơn là với task Image Classification trên tập ImageNet (không sử dụng thêm data từ bên ngoài) nhưng mà do bộ này nặng so với máy mình nên mình sẽ pick một bộ khác gpu friendly hơn aka CIFAR10. Bộ này thì nặng khoảng 162Mb nếu mình nhớ không lầm, cũng 50.000 ảnh train và 10.000 ảnh text, mỗi ảnh có kích thước $32 \times 32$ và là ảnh màu với 3 kênh màu rgb, về class thì có 10 class khác nhau
Trong bài này thì các tác giả sử dụng đầu vào với đầu ra như cái protocol của mô hình ViT/16 cho cả input lẫn output. Nên là mình cũng làm vậy, nhưng mà cái hình này có $32 \times 32$ à nên chia 4 khúc $16 \times 16$ thì nhìn kì kì nên mình chia nó thành 16 khúc $8 \times 8$ nhìn cho nó bớt kì =)))))))))))))). Về batch size thì mình để thành 32, các phương pháp augmentation thì chỉ dùng normalize bình thường thôi, hàm loss dùng Cross Entropy Loss, optimizer thì dùng AdamW.
Trong code mình để trên github là cái mô hình lightweight, đâu đó cỡ 4M tham số. Thì con số này là train dễ dàng trên máy local mọi người nha. Lưu ý thêm là mình có thử với mô hình này với 51M tham số trên con NVIDIA RTX 3090 (thuê cloud gpu chứ đào đâu ra 🥹) thì chạy 10 epoch đâu đó cỡ 15 phút, và mô hình này hội tụ trên tập train rất nhanh (trong khi với 4M như trên github thì không nhanh như vậy). Cái mình muốn nói á là top1-acc của mô hình 51M sau 10 epoch là cỡ 70% cho tập test và 95% cho tập train, trong khi với mô hình 4M thì không được như vậy. Nên là (nói cái này hơi thừa) việc mô hình càng lớn (theo như tác giả xác nhận) thì khả năng mô hình học cũng càng lớn, nói nôm na là khả năng của mô hình scale theo độ lớn của mô hình. À mà thuê GPU như con NVIDIA RTX 3090 là 16k/h nha, như kiểu thuê phòng net (phòng cyber hẳn hoi). Mình thuê ở đây, cực kì phù hợp cho ae nào có mấy model nó nặng vcl mà chạy trên colab nó hơi đuồi.
Thì do là protocol y chang, nên là một lớn chia thành mấy patch nhỏ hơn, nhìn như cái hình này:
Ok, giờ vô nhân vật tiêu điểm, là cái Spatial Gating Unit, code của nó như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class SpatialGatingUnit(nn.Module):
def __init__(self, d_ffn,
seq_len, weight_value=0.05):
super().__init__()
self.norm = nn.LayerNorm(d_ffn//2)
# Setup weight for the spatial projection
self.weight = nn.Parameter(torch.zeros(seq_len,seq_len))
nn.init.uniform_(self.weight, a=-weight_value, b=weight_value)
# Setup bias for the spatial projection
self.bias = nn.Parameter(torch.ones(seq_len))
def forward(self, x):
u, v = x.chunk(2, dim=-1)
v = self.norm(v)
weight, bias = self.weight, self.bias
v = einsum('b n d, m n -> b m d', v, weight) + rearrange(bias, 'n -> () n ()')
return u * v
Phân biệt rõ cái d_model là cái embedding dim, còn cái d_ffn là cái dim của cái channel projection nha mọi người, còn seq_len thì dùng chung, hoặc là token, hoặc là patches.
Giờ tới một block gMLP sẽ nhìn thế này:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class gMLPBlock(nn.Module):
def __init__(self, d_model, d_ffn, seq_len):
super().__init__()
self.norm = nn.LayerNorm(d_model)
self.channel_proj_U = nn.Sequential(
nn.Linear(d_model, d_ffn),
nn.GELU()
)
self.sgu = SpatialGatingUnit(d_ffn, seq_len)
self.channel_proj_V = nn.Sequential(
nn.Linear(d_ffn//2, d_model),
nn.GELU()
)
def forward(self, x):
res = x
x = self.norm(x)
x = self.channel_proj_U(x)
x = self.sgu(x)
x = self.channel_proj_V(x)
return x + res
Đó, như nãy giờ mình đề cập ở trên thôi, vậy thì một khối gMLP hòan chỉnh thì nhìn như này:
1
2
3
4
5
6
7
8
9
10
11
class gMLP(nn.Module):
def __init__(self, d_model, d_ffn, seq_len, num_layers):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(num_layers):
self.layers.append(gMLPBlock(d_model, d_ffn, seq_len))
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
Về cái phần tách hình ra thành các patch sẽ được viết như này:
1
2
3
4
5
6
7
8
class PatchEmbedding(nn.Module):
def __init__(self, patch_size, in_channels, embed_dim):
super().__init__()
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # (B, embed_dim, H, W)
return x.flatten(2).transpose(1, 2) # (B, num_patches, embed_dim)
Về phần quan trọng nhất của cái task phân loại ảnh này là cái model để trả ra cái embedding mà ở đó các token (hoặc patch) đã có được thông tin của nhau, thì được code thế này:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class gMLP_Vision(nn.Module):
def __init__(self, patch_size = 8, num_patches = 16, embed_dim = 768, num_layers = 6):
super().__init__()
self.patch_embed = PatchEmbedding(patch_size=patch_size, in_channels=3, embed_dim=embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=0.1)
self.blocks = gMLP(d_model=embed_dim,
d_ffn=embed_dim*4,
seq_len=num_patches+1,
num_layers=num_layers)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
x = self.blocks(x)
x = self.norm(x)
return x[:, 0]
Ok, cuối cùng thì mình cần 1 cái head để phân loại ảnh, cái này làm đơn giản thôi ae, thì nó như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Image_Classification(nn.Module):
def __init__(self, patch_size = 8, num_patches = 16, embed_dim = 512,
num_layers = 3, fc_dim = 256, num_classes = 10):
super().__init__()
self.model = gMLP_Vision(patch_size=patch_size, num_patches=num_patches, embed_dim=embed_dim, num_layers=num_layers)
self.fc_1 = nn.Linear(embed_dim, fc_dim)
self.act = nn.GELU()
self.head = nn.Linear(fc_dim, num_classes)
def forward(self, x):
x = self.model(x)
x = self.fc_1(x)
x = self.act(x)
x = self.head(x)
return x
Còn code để chạy cái accuracy thì nó như này:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def evaluate_epoch_topk(model, test_dataloader, device, k):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for idx, (inputs, labels) in enumerate(test_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
predictions = model(inputs)
_, predicted = predictions.topk(k, 1, True, True)
total += labels.size(0)
correct += (predicted == labels.view(-1, 1).expand_as(predicted)).sum().item()
topk_acc = correct / total
return topk_acc
for i in range(1,6):
topk = evaluate_epoch_topk(model, testloader, device, i)
print(f"Top-{i} accuracy: {topk:.2f}")
Còn phần preprocess với download ảnh thì làm như torchvision hướng dẫn thôi, mọi người có thể lên đó coi thử.
Thảo luận thêm
Đầu tiên thì blog này có phần phân tích ưu nhược điểm nữa, nhưng mình thấy bài này không nên đặt ra ưu với nhược điểm. Quay lại với ý nghĩa của bài nghiên cứu này, mục đích chính của bài này không phải là đề xuất ra một mô hình mới, một cấu trúc mới. Mà là để lật lại câu hỏi về sự cần thiết của khối attention.
Lý do mình thích bài này là vì nó đặt ra một góc nhìn mới cho một vấn đề nhìn có vẻ cũ, từ đó làm mới vấn đề. Việc tách tính hiệu quả của cấu trúc Transformer ra thành tính chất yếu trong cái inductive bias của công thức attention và khả năng xấp xỉ một cái arbitrary function nào đó lên bàn cân cũng khá mới mẻ. Nên mình thích =))))))
Điều này cho thấy rằng attention might not what we all needed. Có thể với các phương pháp cũ hơn mà mình attention vào nó thì vẫn có thể cho ra các kết quả rất tuyệt vời. Và có thể thấy rằng với cái quadratic complexity thì những mô hình sử dụng cái cơ chế attention khá là trở nên tốn kém khi input đầu vào to hơn, hoặc dài hơn. Thì nói chung là vậy, có thể sau này mình ngẫm ra gì đó hay hơn thì mình bỏ vô đây sau vậy.
🍻🍻🍻 !!! Cheers !!! 🍻🍻🍻
References
The Inductive Bias of ML Models, and Why You Should Care About It
A fAIry tale of the Inductive Bias (này là người ta ghi chữ fairy v á nha ae, chắc chơi chữ)
You Don’t Understand Neural Networks Until You Understand the Universal Approximation Theorem
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale